# a 标签 rel 属性
<a target="_blank" rel="noopener noreferrer" class="hover" href="https://linkmarket.aliyun.com/hardware_store?spm=a2c3t.11219538.iot-navBar.62.4b5a51e7u2sXtw" data-spm-anchor-id="a2c3t.11219538.iot-navBar.62">硬件商城</a>使用 noopener noreferrer 就是告诉浏览器,新打开的子窗口不需要访问父窗口的任何内容,这是为了防止一些钓鱼网站窃取父窗口的信息。
浏览器在打开新页面时,解析到含有 noopener noreferrer 时,就知道他们不需要共享页面内容,所以这时候浏览器就会让新链接在一个新页面中打开了。
# 防抖函数的使用
若直接在 useEffect()中调用防抖函数,会发现防抖不起作用,原因:useEffect 会在每轮渲染结束后执行,在 state 发生改变时,也会重新执行。因而,这里的 value 每变化一次,debounce 函数就会重新生成一次,其内部逻辑就会执行一次。用 ref 保存一下防抖函数,后面再触发 useEffect 时,就不会生成新的防抖函数了。
直接使用 lodash 的 debounce 函数。通过计数。
const fetchRef = useRef(0);
const debounceFetcher = React.useMemo(() => {
const loadOptions = (value: string) => {
fetchRef.current += 1;
const fetchId = fetchRef.current;
setLoading(true);
getDataList(value).then((res) => {
if (fetchId !== fetchRef.current) {
return;
}
if (res.code === 1) {
setDataList(res.data);
} else {
setDataList([]);
}
setLoading(false);
});
};
return debounce(loadOptions, debounceTimeout);
}, [xxx, yyy]);
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
- 保存这个防抖函数
import { debounce } from "lodash";
const useMyDebounce = (fun, wait, options) => {
const myRef = useRef();
if (!myRef.current) {
myRef.current = debounce(fun, wait, options);
}
return myRef.current;
};
export default useMyDebounce;
2
3
4
5
6
7
8
9
10
# Nignx 使用 njs
# 前端跨域
# 同源
同源:same-origin: 何为同源:url 是由协议、域名、端口和路径组成 如果两个路径的协议、域名、端口都相同则表示在同一个域上,即同源;在浏览器上 <script>、<img>、<link>、<iframe>等标签都可以加载跨域资源且不受同源策略限制。
# 跨域
- JSONP: 通过 javascript callback 的形式实现跨域访问,服务器收到请求后,将数据放在一个指定名字的回调函数里传回来;
- postMessage / Channel Messaging API;
- window.name: window.name + iframe 需要目标服务器响应 window.name,window 对象有一个 name 属性,该属性有个特征:即在一个窗口(window)的生命周期内,窗口载入的所有的页面都是共享一个 window.name 的,每个页面对 window.name 都有读写的权利,window.name 是持久存在一个窗口载入过的所有页面中的;
- document.domain: 当两个页面的 document.domain 都设置为 ericyangxd.top 也就是同一个二级域名的时候,浏览器就将两个来源视为同源。这时候主页面就可以和 iframe/子页面 进行通信了。Chrome 决定在 101 版本禁用掉它。解决办法:给你的网页增加下面这个 Header 就可以了:
Origin-Agent-Cluster: ?0. - CORS: Nginx 设置 header:
Access-Control-Allow-Origin: *; - websocket: 单独的持久连接上提供全双工、双向通信;
# 跨域请求服务端有没有收到,收到的话是否执行,执行的话是否有返回,返回的 response 在哪里
- 简单请求:不管是否跨域,只要发出去了,一定会到达服务端并被执行,浏览器只会隐藏返回值
- 复杂请求:先发预检,预检不会真正执行业务逻辑,预检通过后才会发送真正请求并在服务端被执行
在发送真正的请求之前,浏览器会先发送一个 Preflight 请求,也就是我们常说的预检请求,它的方法为 OPTIONS。当预检请求到达服务端时,服务端是不会真正执行这个请求的逻辑的,只会在这个请求上返回一些 HTTP Header,以此来告诉客户端是不是要发送真正的请求。
一旦浏览器把请求判定为「简单请求」,浏览器就不会发送预检请求了。
浏览器判定请求是否为简单请求要同时满足以下四个条件:
- 使用下列方法之一:
- GET
- HEAD
- POST
- 只使用了如下的安全 Header,不得人为设置其他 Header
- text/plain
- multipart/form-data
- application/x-www-form-urlencoded
- Content-Type 的值仅限于下列三者之一:
- Accept
- Accept-Language
- Content-Language
- 请求中的任意 XMLHttpRequest 对象均没有注册任何事件监听器;XMLHttpRequest 对象可以使用 XMLHttpRequest.upload 属性访问。
- 请求中没有使用 ReadableStream 对象。
所以,如果你发送的是一个简单请求,这个请求不管是不是会受到跨域的限制,只要发出去了,一定会在服务端被执行,浏览器只是隐藏了返回值而已。
# Vue 跨域配置
利用 http-proxy-middleware 代理解决;
// vue.config.js
devServer:{
proxy:{
"/api":{
target:"https://****.com" //数据接口的地址
changeOrigin:true, // 允许跨域
secure:false, // 允许运行在https上
pathRewrite: { //如果你不想总是传递 /api,可以重写路径
'^/api': ''
}
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
# Nginx 跨域配置
- 跨域主要涉及四个响应头:
- Access-Control-Allow-Origin: 设置允许跨域请求源地址(预检和正式请求在跨域时都会验证)
- Access-Control-Allow-Headers: 跨域允许携带的特殊头信息字段(只在预检请求验证)
- Access-Control-Allow-Methods: 跨域允许的请求方法(只在预检请求验证)
- Access-Control-Allow-Credentials: 是否允许跨域使用 cookies
- CORS 机制跨域会首先进行 preflight 预检(一个 OPTIONS 请求),该请求成功后才会发送真正的请求
- 示例:
server {
listen 22222;
server_name localhost;
location / {
if ($request_method = 'OPTIONS') {
add_header Access-Control-Allow-Origin 'http://localhost:8080';
add_header Access-Control-Allow-Headers '*';
add_header Access-Control-Allow-Methods '*';
add_header Access-Control-Allow-Credentials 'true';
return 204;
}
if ($request_method != 'OPTIONS') {
add_header Access-Control-Allow-Origin 'http://localhost:8080' always;
add_header Access-Control-Allow-Credentials 'true';
}
proxy_pass http://localhost:8090;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# BFF
BFF(Backend for Frontend)层,主要就是就是为了前端服务的后端。与其说是后端,不如说是各种端(Browser、APP、miniprogram)和后端各种微服务、API 之间的一层胶水代码。这层代码主要的业务场景也比较集中,大多数是请求转发、数据组织、接口适配、鉴权和 SSR。在这种业务场景下,采用大前端的开发模式,会提升业务的迭代效率。
- 前端和后端都使用 JavasScript,技术栈是统一的。从写代码,到编译、打包、脚手架、组件化、包管理,再到 CICD,采用同一套都不是问题。
- Client Side JavaScript 和 Server Side JavaScript 本身就有很多可服用的代码,例如现在行业里有很多同构代码的 CSR 和 SSR 解决方案。
- 优化研发组织结构。大前端的开发模式,让接口定义、接口联调、环境模拟等,原来需要两种不同技术能力栈的工程师互相协作的模式,变为同一种技术技术能力栈的工程师独立完成的模式,让沟通和推动的成本降到最低。
# moment
时间:var time = new Date(); // Tue Aug 28 2018 09:16:06 GMT+0800 (中国标准时间)
时间戳:var timestamp = Date.parse(time); // 1535419062000 (Date.parse() 默认不取毫秒,即后三位毫秒为 0)
moment 转时间戳:moment(time).valueOf(); // 1535419062126
moment 转时间:moment(timestamp).format(); // 2018-08-28T09:17:42+08:00
# new URL() 和 window.location
# location 对象
// window.location
/*
https://www.baidu.com/s?wd=Reflect.%20defineProperty&rsv_spt=1#123
*/
const { href, origin, host, port, protocol, pathname, hash, search } = window.location;
console.log(href); // 获取整个URL xxx
console.log(origin); // 协议+域名+端口 https://www.baidu.com
console.log(host); // 主机名+端口号(http或者https会省略端口号) www.baidu.com
console.log(port); // '' http默认端口80 https默认端口443
console.log(protocol); // 协议 https:
console.log(pathname); // 除了域名的路由地址路径
console.log(hash); // 路径带#的参数
console.log(search); // 地址?后面所有参数
2
3
4
5
6
7
8
9
10
11
12
13
在 location.search、location.hash、location.origin、location.href 是通常项目中几个比较高频的获取当前地址的一些参数方法,不过注意只有 location.origin 这个是只读的,其他 API 都是可读可写.
# URL
const url = new URL("https://www.baidu.com/s?wd=Reflect.%20defineProperty&rsv_spt=1#123");
console.log(url.search); // ?wd=Reflect.%20defineProperty&rsv_spt=1
console.log(url.hash); // #123
console.log(url.origin); // https://www.baidu.com
console.log(url.href); // 'https://www.baidu.com/s?wd=Reflect.%20defineProperty&rsv_spt=1#123'
2
3
4
5
URL 这个原生构造的地址中属性与 location 获取地址上的通用属性都基本一样。
唯一的区别是,location 多了 replace 与 reload 方法,URL 除了拥有 location 的通用属性,没有 replace 与 reload 方法,但是他具备一个获取参数的一个 searchParamsAPI.
# searchParams
// 返回 URLSearchParams 的对象
console.log(url.searchParams);
// { 'wd' => 'Reflect. defineProperty', 'rsv_spt' => '1' }
// 可以替代qs.stringify()
console.log(url.searchParams.toString());
// wd=Reflect.+defineProperty&rsv_spt=1
// 相当于 URLSearchParams(search) ,不用考虑'?'
const { search } = this.props.location;
const { id, name } = qs.parse(search.replace(/^\?/, ""));
2
3
4
5
6
7
8
9
10
11
- url query params 解析转换
- 原生 Object 提供了一个
fromEntriesAPI,它可以将 entries 数据还原成以前的 obj。
function formateQueryUrl() {
const { search } = window.location;
// 以?分割,获取url上的真正的参数
const [, searchStr] = search.split("?");
// 以&分割前后参数
const arr = searchStr.split("&");
const ret = {};
arr.forEach((v) => {
const [key, val] = v.split("=");
ret[key] = val;
});
return ret;
}
// 与上面formateQueryUrl方法等价
function eazyFormateQueryUrl() {
const url = new URL(window.location);
return Object.fromEntries(url.searchParams.entries());
}
// 如果当前浏览器地址 https://www.badu.com?a=1&b=2
// {a:1,b:2}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# Cookie
# 作用
因为 HTTP 是无状态的,所以为了协助 Web 保持状态,Cookie 诞生了。主要用于以下三个方面:
- 会话状态管理(如用户登录状态、购物车、游戏分数或其它需要记录的信息)
- 个性化设置(如用户自定义设置、主题等)
- 浏览器行为跟踪(如跟踪分析用户行为等)
# 设置
| 平台 | 操作示例 | 说明 |
|---|---|---|
| 服务端 | set-cookie: <cookie-name>=<cookie-value> | 服务端通过设置 set-cookie 控制 Cookie |
| 浏览器 document.cookie | document.cookie = "name=scar"; | 获取并设置与当前文档相关联的 cookie,操作不灵活。只能设置非 HttpOnly 的 Cookie。 |
| 浏览器 Cookie Store API | cookieStore.set("name", "scar"); | 新特性,仅支持在 HTTPS 使用,目前还在实验阶段。 |
# 伪代码/使用
- 服务端,例 nodejs:
const http = require("http");
http
.createServer((req, res) => {
if (req.url === "/read") {
// 读取 Cookie
res.end(`Read Cookie: ${req.headers.cookie || ""}`);
} else if (req.url === "/write") {
// 设置 Cookie
res.setHeader("Set-Cookie", [
`name=scar;`,
//set-cookie 属性大小写不敏感,你可以写成 path=/ 或者 Path=/
`language=javascript;Path=/; HttpOnly;Expires=${new Date(Date.now() + 1000).toUTCString()};`,
]);
res.end("Write Success");
} else if (req.url === "/delete") {
// 删除 cookie
res.setHeader("Set-Cookie", [
// 设置过期时间为过去的时间
`name=;expires=${new Date(1).toUTCString()}`,
// 有效期 max-age 设置成 0 或 -1 这种无效秒,让 cookie 当场去世
// 有些浏览器不支持 max-age 属性,所以用此方法需要考虑兼容性
"language=javascript; max-age=0",
]);
res.end("Delete Success");
} else {
res.end("Not Found");
}
})
.listen(3000);
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
- 客户端,通过浏览器方法 document.cookie 读写当前界面的 Cookie,只能设置非 HttpOnly 的 Cookie。。
// 编辑 Cookie,必须一个一个设置!!!不能多个一起设置!!!
document.cookie = "name=scar";
document.cookie = "language=javascript";
// 读取 Cookie
console.log(document.cookie);
//name=scar; language=javascript
// 删除 Cookie
document.cookie = "name=scar;expires=Thu, 01 Jan 1970 00:00:01 GMT";
2
3
4
5
6
7
8
9
- 客户端:Cookie Store API,目前正在试验阶段,Firefox、Safari 浏览器 还不支持,所以不建议在生产环境使用,相信在将来我们会用上它更方便地操作 Cookie。
// 读取 Cookie,返回的是Promise,所以要用await!!!
await cookieStore.get("enName");
await cookieStore.getAll();
// 设置 Cookie
const day = 24 * 60 * 60 * 1000;
cookieStore
.set({
name: "enName",
value: "scar",
expires: Date.now() + day, // 过期时间,默认为会话关闭时间
domain: "scar.site", // 生效域名,是接受请求的域名
path: "/report_mgmt", // 生效路径,子路径也会被匹配
sameSite: "none", // 允许服务器设定 Cookie 不随着跨站请求一起发送,Lax|Strict|None,服务器要求某个 Cookie 在跨站请求时不会被发送,从而可以阻止跨站请求伪造攻击。限制了发送 Cookie 的域名
secure: false, // 仅 HTTPS 可用,标记为 Secure 的 Cookie 只应通过被 HTTPS 协议加密过的请求发送给服务端,因此可以预防 man-in-the-middle 攻击。
maxAge: 10000, // 有效期,单位秒,秒数为 0 或 -1 将会使 cookie 直接过期,如果 Expires 和Max-Age 同时存在时,Max-Age优先级更高。
sameParty: false, // 允许特定条件跨域共享 Cookie
priority: "Medium", // 优先级,仅 Chrome 支持, Low|Medium|High,如果设置了 Priority,Chrome 会先将优先级低的清除,并且每种优先级 Cookie 至少保留一个。
httpOnly: false, // 设置了 HttpOnly 属性的 cookie 不能使用 JavaScript 经由 document.cookie 属性、XMLHttpRequest 和 Request APIs、Cookie Store APIs 进行访问。
})
.then(
function () {
console.log("It worked!");
},
function (reason) {
console.error("It failed: ", reason);
}
);
// 删除 Cookie
await cookieStore.delete("session_id");
// 监听 Cookie 变化
cookieStore.addEventListener("change", (event) => {
for (const cookie of event.changed) {
if (cookie.name === "name") sessionCookieChanged(cookie.value);
}
for (const cookie of event.deleted) {
if (cookie.name === "enName") sessionCookieChanged(null);
}
});
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
# Q&A
# 请求时,哪些 Cookie 会被带到后端?由什么决定?
- 浏览器请求头:
Cookie: token=abc123 - Cookie 本质由服务器下发或 JS 写入,浏览器存储和管理。
- 前端只能操作非 HttpOnly 的 Cookie。
- 发送哪些 cookie 完全由浏览器根据域、路径、安全等属性决定,不需要开发者手动指定。
- AJAX 跨域需注意 CORS 配置以及 withCredentials,否则不会自动发送 cookie。
- 域名和路径(Domain & Path):浏览器只会带上“当前请求 URL”匹配的域名和路径范围内的 Cookie。
- 安全属性(Secure):如果设置了 Secure 属性,那么浏览器只有在 HTTPS 协议下才会带上该 Cookie,如果是 HTTP 协议,浏览器会忽略该 Cookie。
- HttpOnly:如果设置了 HttpOnly 属性,那么通过 JavaScript 脚本将无法读取到 Cookie 信息,这样能有效的防止 XSS 攻击。
- SameSite 属性:
- Lax:默认。部分跨站请求不带(比如 a 标签、GET 表单),一般导航或同源会带
- Strict:严格模式,任何第三方场景都不会带
- None:总是允许跨站携带,但必须配合 Secure 属性一起使用,否则无效。
- 请求方式:通常 GET、POST 都会自动按规则附带符合条件的 Cookie。跨域 AJAX 请求还受 CORS 策略影响,需要配置
withCredentials=true并且后端允许。
# Cookie 的限制
- 大小限制
大多数浏览器支持最大为 4KB 的 Cookie,4KB 是针对 Cookie 单条记录的 Value 值。
- 数量限制
Cookie 有数量限制,而且只允许每个站点存储一定数量的 Cookie,当超过时,最早过期的 Cookie 便被删除,或者优先级低的会被干掉。在 150-180 左右。
实际上影响 Cookie 被删除的要素不止是 Expires 和 Max-Age,还有 Priority、Secure。
# 和 Cookie 相关的不安全事件有哪些?
- CSRF 跨站请求攻击:攻击者通过一些技术手段欺骗用户的浏览器去访问一个自己曾经认证过的网站并运行一些操作(如发邮件,发消息,甚至财产操作如转账和购买商品)。
- 通过设置 SameSite 可以防止跨域发送 Cookie,抵御 CSRF。
XSS 跨站脚本攻击:是一种网站应用程序的安全漏洞攻击。通常指的是通过利用网页开发时留下的漏洞,通过巧妙的方法注入恶意指令代码到网页,使用户加载并执行攻击者恶意制造的网页程序。攻击成功后,攻击者可能得到 Cookie 从而实现攻击。
同名 Cookie 发送时,优先级如何判断?
Cookie 发送顺序:Path 属性较长的应该在前面;如果 Path 路径一样,创建时间早的在前面。
除了考虑发送顺序,还要考虑不同的服务器框架可能有不同的接收逻辑,所要尽量避免出现同名 Cookie,减少端表现不统一带来的不确定性。后端也不应该依赖 cookie 的顺序,因为这个顺序是不确定的。
- 如何快速调试 Cookie
- 浏览器控制台->Applications 下,通过分析 Cookie 属性来定位问题。
# 多个域名或多级域名下的 cookie 优先级
- 场景:一个一级域名下面还有多个二级域名,当我们在一级域名下登录之后,有一个 cookie1,如果又去二级域名下也写入一个 cookie1,那么向二级域名请求后端的时候,这两个同名 cookie1 会携带哪个?优先级如何?
- A:两个同名 cookie1 都会被请求头带上发送给服务端,不会说有什么 domain 的优先级,导致后端只收到“优先级高”的一个。
- A:后端取到的,只有 cookie 的 name 与 value,所以想通过 domain 过滤出需要的 cookie 是不可取的。
- A:某些情况下,后端收到 cookie 还是有一个稳定的顺序的(但是不应该依赖这个顺序):path 更长的 cookie 更靠前;path 相等的,更早创建的 cookie 更靠前。
# SameSite 和 Domain 的区别
- SameSite:可以设置某个 Cookie 在跨站请求时不会被发送,从而可以阻止跨站请求伪造攻击 CSRF。默认:LAX;
- Domain:指定 cookie 可以送达的主机名。如果设置为“.google.com”,则所有以“google.com”结尾的域名都可以访问该 Cookie。注意第一个字符必须为“.”。为了保证安全性,cookie 无法设置除当前域名或者其父域名之外的其他 domain。domain 默认为当前域名(不包含子域名)。请求这些 domain 下的接口时会自动带上符合条件的 cookie。
- Domain:对于前端来说,只要请求的目标地址匹配 Domain 规则,那 Cookie 就会被发送过去,即 domain 是接受/请求 cookie 的域名。对于后端来说,set-cookie 时,如果指定了 server 服务的域名,那么在服务端生成的 cookie 的 domain 只能指定为相应的 domain 或父 domain,其他 domain 都无法成功设置 cookie。
- Path:对于 domain 相同,path 不同的同名 cookie,请求该 domain 下的接口时同名 cookie 也会都被带上。
- cookie 的作用域是 domain 本身以及 domain 下的所有子域名。
# 如何控制浏览器资源加载优先级之 Priority Hints
- 常规做法:
- 根据期望的资源的下载顺序放置资源标签,例如
<script>和<link>,具有相同优先级的资源通常按照它们被放置的顺序加载。 - 使用 preload 属性提前下载必要的资源,特别是对于浏览器早期不易发现的资源。
- 使用 async 或 defer 下载非首屏不需要阻塞的资源。
- 延迟加载一些首屏内容,以便浏览器可以将可用的网络带宽用于更重要的首屏资源。
async 标记异步下载,异步执行,多条 js 可以并行下载,当 js 下载完成后会立即(尽快)执行,多条 js 不会互相等待,不能确保彼此的先后顺序。 defer 标记异步下载,多条 js 可以并行下载,不过当 js 下载完成之后不会立即执行,而是会等待解析完整个 HTML 之后在开始执行,而且多条 defer 标记的 js 会按照顺序执行。defer 脚本会在DOMContentLoaded和 load 事件之前执行。 如果两个 script 之间没有依赖关系并且可以尽快执行的更加适合使用 async,反之如果两个 script 之间有依赖关系,或者希望优先解析 HTML,则 defer 更加适合。
- 特殊情况:
- 网站现在有多个首屏图像,但它们并具有相同的优先级,比如在轮播图中只有第一张图需要更高的优先级。
- 将
<script>声明为 async 或 defer 可以告诉浏览器异步加载它们。但是,根据我们上面的分析,这些<script>也被分配了 “低” 优先级。但是你可能希望在确保浏览器异步下载它们的同时提高它们的优先级,尤其是一些对用户体验至关重要脚本。 - 浏览器为 JavaScript fetch API 异步获取资源或数据分配了高优先级,但是某些场景下你可能不希望以高优先级请求所有资源。
- 浏览器为 CSS、Font 分配了同样的高优先级,但是并不是所有 CSS 和 Font 资源都是一样重要的,你可能需要更具体的指定它们的优先级。
- 可行的解决方法试验特性 —— Priority Hints:
- 可以使用一个 importance 属性来更细粒度的控制资源加载的优先级,包括 link、img、script 和 iframe 这些标签。
- high:你认为该资源具有高优先级,并希望浏览器对其进行优先级排序。
- low:你认为该资源的优先级较低,并希望浏览器降低其优先级。
- auto:采用浏览器的默认优先级。
- 例:
<link rel="preload" href="/js/script.js" as="script" importance="low">
- 实际应用
- 提升 LCP 图像的优先级
- 降低首屏图片的优先级
- 降低预加载资源的优先级
- 改变脚本的优先级,配合 async/defer
- 降低不太关键的数据请求的优先级
# HTML - link 标签
<link rel="preload" href="style.css" as="style">,as 属性可以指定预加载的类型,除了 style 还支持很多类型,常用的一般是 style 和 script,css 和 js,image 等。- 使用 link 的 preload 属性预加载一个资源。
- prefetch 和 preload 差不多,prefetch 是一个低优先级的获取,通常用在这个资源可能会在用户接下来访问的页面中出现的时候。对当前页面的要用 preload,不要用 prefetch,可以用到的一个场景是在用户鼠标移入 a 标签时进行一个 prefetch。
- preconnect 和 dns-prefetch 做的事情类似,提前进行 TCP,SSL 握手,省去这一部分时间,基于 HTTP1.1(keep-alive)和 HTTP2(多路复用)的特性,都会在同一个 TCP 链接内完成接下来的传输任务。
<script src="" crossorigin="anonymous"></script>,crossorigin 可以使用本属性来使那些将静态资源放在另外一个域名的站点打印错误信息。通过window.onerror捕获错误信息。
# 区分 link 的 rel 属性的几个 pre 值
- preload:预加载,允许浏览器在页面解析时提前加载特定的资源,不会阻塞页面渲染。浏览器会立即开始下载资源,并且会立即开始解析资源,可用于优先加载重要资源,确保在需要时资源已准备好。有助于减少页面渲染时间,提高用户体验。
<link rel="preload" href="style.css" as="style" />
<link rel="preload" href="script.js" as="script" />
<link rel="preload" href="image.jpg" as="image" />
2
3
- prefetch:预获取,允许浏览器在空闲时间加载可能在未来某个时间点需要的资源。prefetch 通常用于非关键资源,这些资源可能在用户导航到其他页面时使用,改善用户在后续操作中的体验。加载资源的优先级较低,如果当前页面不需要该资源,prefetch 的加载不会影响当前页面的渲染性能。
<link rel="prefetch" href="next-page.html" /> <link rel="prefetch" href="styles-next.css" />
- prerender:预渲染,在用户访问某个页面之前,提前渲染整个页面。这样,当用户真的导航到这个页面时,可以立即显示,而不必等待页面加载。完全渲染:prerender 会创建一个完整的页面副本,包括其 DOM、样式和 JavaScript 内容,用户在访问时可以几乎即时呈现。资源消耗高:由于是完整的页面渲染,prerender 会占用更多的资源和带宽,因此应谨慎使用,特别是在资源有限的环境下。适用于用户导航:通常用于预测用户即将访问的页面。
<link rel="prerender" href="next-page.html" />
- preconnect:预连接,允许浏览器在请求资源之前,提前建立与目标服务器的连接,包括 DNS 解析、TLS 握手和 TCP 连接。这样在真正请求资源时,连接已经就绪,可以直接传输数据。减少了用户与外部资源交互时的延迟。适合用于加载外部资源的页面,以加速请求。不要滥用:每一个 preconnect 都会占用浏览器的连接资源,提前连接的域名过多可能会浪费资源。现代浏览器支持良好:大多数现代浏览器都支持 preconnect,但可以结合 dns-prefetch 作为回退方案。
<link rel="preconnect" href="https://example.com" />
<!-- 如果第三方域名需要携带跨域请求的凭据(如 cookies),则需要指定 crossorigin 属性: -->
<link rel="preconnect" href="https://example.com" crossorigin="anonymous" />
2
3
- dns-prefetch:是一种预解析域名的技术,允许浏览器提前解析 DNS,以减少后续请求的延迟。减少了访问外部资源时的 DNS 查询时间。适合于引用许多外部资源的页面。页面中会请求的资源来自第三方域名,例如:CDN、第三方广告、分析服务等。只会提前完成域名解析,不会建立连接(即不会完成 TCP 和 TLS 握手)。对于一些页面中静态资源的域名,现代浏览器会自动执行 dns-prefetch,但手动添加可以确保关键域名被优先处理。对于明显依赖的第三方资源域名(如分析服务、广告服务),建议显式使用 dns-prefetch。
<link rel="dns-prefetch" href="//example.com" />
# 预加载的推荐做法
使用 js 在页面加载完成后再动态插入预加载标签,因为目前的浏览器对 prefetch 的实现方式还不太完善,可能会出现预加载资源(往往会过早加载)与关键资源争夺带宽的情况,所以建议使用 js 在 load 事件触发之后,动态插入 link 标签到 head 中的方式。
window.addEventListener("load", () => {
const link = document.createElement("link");
link.rel = "prefetch";
link.href = "https://example.com/script.js";
link.as = "script";
document.head.appendChild(link);
});
2
3
4
5
6
7
# 对 lodash 进行 tree-shaking
Tree-shaking 指的是消除没被引用的模块代码,减少代码体积大小,以提高页面的性能,最初由 rollup 提出。
webpack2 加入对 Tree-shaking 的支持,webpack4 中 Tree-shaking 默认开启,Tree-shaking 基于 ESModule 静态编译而成,所以如果想要生效,在写代码的时候注意不要用 CommonJS 的模块,同时也要注意不要让 babel 给编译成 CommonJS 的形式。
对于一些第三方库来说为了兼容性考虑通常入口文件都是 CommonJS 的形式,这时想要成功抖掉不需要的部分通常有两种方式。
lodash 默认是 CommonJS 的形式,使用常规的方法 import { cloneDeep } from 'lodash'; 导入后,webpack 会把整个 lodash 打包进来,这对于只用到了一个函数的我们的来说显然不可接受,此时可以改写为:
import cloneDeep from "lodash/cloneDeep";
或者如果提供了 ESModule 的版本也可以直接使用:
import { cloneDeep } from 'lodash-es;
前者是精准导入不依赖 re-exports,后者则是一个正经的 Tree-shaking。
webpack4+无需配置默认会压缩代码,如果你想亲自试试,Js 可选 UglifyJS,CSS 可选 mini-css-extract-plugin。
使用动态 import()代替静态 import 做条件渲染的懒加载。其实具体到组件内部,也可以用同样的方式将一些基于判断条件的子组件/第三方库通过 import()的方式导入,这样 webpack 在打包时会单独将它列为一个块,当符合判断条件时才会尝试去加载这个文件。
服务器端渲染出来的 HTML 部分最好不要超过 14kb,TCP 慢开始的规则让第一个 TCP 包的大小是 14kb,这是与网站交互会接受到的第一个包。
# 页面间通信
- url 传参
- postmessage
- localStorage
- WebSocket
- SharedWorker
- Service Worker
- BroadcastChannel API
# url 传参
- A 页面通过 url 传递参数与 B 页面通信,同样通过监听 hashchange 事件,在页面 B 关闭时与 A 通信。
let windowObjectReference = window.open(strUrl, strWindowName, [strWindowFeatures]);
- strUrl === 要在新打开的窗口中加载的 URL。
- strWindowName === 新窗口的名称。如果 strWindowName 已经存在,则按照指定的 strWindowName 打开新窗口,否则按照指定的名称创建一个新窗口。可以限制打开的标签页的数量!很有用。
window.open('xxx?xx=xx', 'music');这样只会新开一个 tab 播放音乐,后续切歌也仍然在这个 tab 上播放。但是会刷新页面。 - strWindowFeatures === 一个可选参数,列出新窗口的特征(大小,位置,滚动条等)作为一个 DOMString。-- menubar, location, resizable, scrollbars, status...
- 返回值 WindowObjectReference:打开的新窗口对象的引用。如果调用失败,返回值会是 null 。如果父子窗口满足“同源策略”,你可以通过这个引用访问新窗口的属性或方法。
- 监听方法
// A.html
window.addEventListener(
"hashchange",
function () {
// 监听 hash
alert(window.location.hash);
},
false
);
// B.html
window.onbeforeunload = function (e) {
window.open("A.html#close", "A");
return "确定离开此页吗?";
};
2
3
4
5
6
7
8
9
10
11
12
13
14
- B 页面正常关闭,如何通知 A 页面:页面正常关闭时,会先执行 window.onbeforeunload ,然后执行 window.onunload ,我们可以在这两个方法里向 A 页面通信。
# postMessage
postMessage 是 h5 引入的 API,postMessage() 方法允许来自不同源的脚本采用异步方式进行有效的通信,可以实现跨文本文档、多窗口、跨域消息传递,多用于窗口间数据通信,这也使它成为跨域通信的一种有效的解决方案。
// A.html
window.name = "A";
function openB() {
window.open("B.html?code=123", "B");
}
window.addEventListener("message", receiveMessage, false);
function receiveMessage(event) {
console.log("收到消息:", event.data);
}
// B.html
window.name = "B";
function sendA() {
let targetWindow = window.opener;
targetWindow.postMessage("Hello A", "http://localhost:3000");
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# localStorage
- localStorage 仅允许你访问一个 Document 源(origin)的对象 Storage;存储的数据将保存在浏览器会话中。如果 A 打开的 B 页面和 A 是不同源,则无法访问同一 localStorage。
- 无论数据存储在 localStorage 还是 sessionStorage ,它们都特定于页面的协议。localStorage 类似 sessionStorage,但其区别在于:存储在 localStorage 的数据可以长期保留,没有过期时间设置;而当页面会话结束——也就是说,当页面被关闭时,存储在 sessionStorage 的数据会被清除 。
- 可以通过挂载 iframe 给 localStorage 扩容。通过 postMessage 通信。
- 存储在 sessionStorage 或 localStorage 中的数据特定于页面的协议。也就是说 http://example.com 与 https://example.com 的 sessionStorage 相互隔离。而同源页面共享 Cookie,只要在同一个浏览器中,无论是否新窗口,都可以访问,修改会立即同步到所有同源页面。
- 被存储的键值对总是以 UTF-16 DOMString 的格式所存储,其使用两个字节来表示一个字符。对于对象、整数 key 值会自动转换成字符串形式。
- 修改会触发所有同源页面的 storage 事件。
# sessionStorage
- 页面会话在浏览器打开期间一直保持,并且重新加载或恢复页面仍会保持原来的页面会话。
- 在新标签或窗口打开一个页面时会「复制」顶级浏览会话的上下文作为新会话的上下文,这点和 session cookies 的运行方式不同。彼此之间是独立的,不会相互影响。
- 打开多个相同的 URL 的 Tabs 页面,会创建各自的 sessionStorage。也就是说彼此之间是独立的,不会相互影响。
- 关闭对应浏览器标签或窗口,会清除对应的 sessionStorage。
- 注意:sessionStorage 不能在多个窗口或标签页之间共享数据,但是当通过
window.open或链接(<a target="_blank">)打开新页面时(不能是新窗口),新页面会复制前一页的 sessionStorage。但注意,这个复制是一次性的,之后两个页面的 sessionStorage 就独立了。也就是说,在父页面中后续对 sessionStorage 的修改不会反映到子页面,同样子页面的修改也不会影响父页面。而且也不能互相访问。
- sessionStorage 顾名思义是针对一个 session 的数据存储,生命周期为当前窗口,一旦窗口关闭,那么存储的数据将被清空。最后还有一个很主要的区别同一浏览器的相同域名和端口的不同页面间可以共享相同的 localStorage,但是不同页面间无法共享 sessionStorage 的信息。
- 比如:打开了两个百度首页 A 和 B,在 A 的 localStorage 中添加删除或修改某个 key/value,在 B 中也能同步看到 localStorage 中数据的变化。而对于这两个页面的 sessionStorage,修改 A 的 sessionStorage 并不会同步到 B 页面。
- 通信方法:不同 tab 之间可以借用 localStorage 的改变来主动修改 sessionStorage,这里要用到一个监听事件
storage,用于监听 localStorage 的变化,然后同步更新 sessionStorage。PS:在 A 页面修改 localStorage,B 页面可以监听 storage 事件监听到;在 A 页面修改 sessionStorage,B 页面是无法监听到变化的。
window.addEventListener("storage", function (event) {
// event.key:确认修改的locaStorage变化key,event.newValue:修改后的值,event.url:url,event.type:'storage'
if (event.key == "token") {
sessionStorage.setItem("token", event.newValue);
}
});
2
3
4
5
6
- 通过
window.open(strUrl, strWindowName, [strWindowFeatures])打开一个新的同源 tab 时,新的 tab 页会复制一份 sessionStorage。
(function () {
// 判断当前页面是否存在sessionStorage
if (!sessionStorage.length) {
// 这个调用能触发目标事件,从而达到共享数据的目的(若不存在则加上一个localStorage Item,key=getSessionStorageData)
localStorage.setItem("getSessionStorageData", Date.now());
}
// 该事件是核心,增加window监听事件
window.addEventListener("storage", function (event) {
// 已存在的标签页会收到这个事件,如果监听到的事件key是getSessionStorageData
if (event.key == "getSessionStorageData") {
// 再新增一个localStorage Item,key=sessionStorageData,value就是当前的sessionStorage
localStorage.setItem("sessionStorage", JSON.stringify(window.sessionStorage));
// 删除localStorage中key=sessionStorageData的item,同时写入和删除,不留下localSorage的记录。
localStorage.removeItem("sessionStorage");
}
if (event.key == "sessionStorageData" && !sessionStorage.length) {
// 新开启的标签页会收到这个事件,把sessionStorageData的资料parse出来
const data = JSON.parse(event.newValue);
// 赋值到当前页面的sessionStorage中
for (key in data) {
window.sessionStorage.setItem(key, data[key]);
}
}
// ===== 加下面这段 =====
if (event.key === "logout") {
// 接收到logout事件,进行sessionStorage的清除和页面reload
window.sessionStorage.clear();
window.location.clear();
}
});
})();
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
# WebSocket
基于服务端的页面通信方式,服务器可以主动向客户端推送信息,客户端也可以主动向服务器发送信息,是真正的双向平等对话,属于服务器推送技术的一种。
# SharedWorker
SharedWorker 接口代表一种特定类型的 worker,可以从几个浏览上下文中访问,例如几个窗口、iframe 或其他 worker。它们实现一个不同于普通 worker 的接口,具有不同的全局作用域, SharedWorkerGlobalScope 。
// A.html
var sharedworker = new SharedWorker("worker.js");
sharedworker.port.start();
sharedworker.port.onmessage = (evt) => {
// evt.data
console.log(evt.data); // hello A
};
// B.html
var sharedworker = new SharedWorker("worker.js");
sharedworker.port.start();
sharedworker.port.postMessage("hello A");
// worker.js
const ports = [];
onconnect = (e) => {
const port = e.ports[0];
ports.push(port);
port.onmessage = (evt) => {
ports
.filter((v) => v !== port) // 此处为了贴近其他方案的实现,剔除自己
.forEach((p) => p.postMessage(evt.data));
};
};
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
# Service Worker
基于 web worker(一个独立于 JavaScript 主线程的独立线程,在里面执行需要消耗大量资源的操作时不会堵塞主线程)。
Service Worker 是一个可以长期运行在后台的 Worker 线程,充当一个服务,能够实现与页面的双向通信。最常见用途就是拦截和处理网络请求、计算、数据离线缓存。
多页面共享间的 Service Worker 可以共享,将 Service Worker 作为消息的处理中心(中央站)即可实现广播效果。
Service Worker 可以拦截并修改用户的请求,或者直接向用户发出回应,不用联系服务器,这使得用户可以在离线情况下使用网络应用。它还可以在本地缓存资源文件,直接从缓存加载文件,因此可以加快访问速度。
Service Worker 不能直接操作 DOM。可以访问 cache 和 indexDB。支持推送,并且可以让开发者自己控制管理缓存的内容以及版本。
它设计为完全异步,同步 API(如 XHR 和 localStorage)不能在 service worker 中使用。
出于安全考量,Service workers 只能由 HTTPS 承载。
在 Firefox 浏览器的用户隐私模式,Service Worker 不可用。
其生命周期与页面无关(关联页面未关闭时,它也可以退出,没有关联页面时,它也可以启动)。
为了节省内存,Service worker 在不使用的时候是休眠的。它也不会保存数据,所以重新启动的时候,为了拿到数据,最好把数据放在 IndexedDb 里面。
// 注册:service worker 不支持跨域脚本。另外,sw.js必须是从 HTTPS 协议加载的。
navigator.serviceWorker
// scope 参数是可选的,可以用来指定你想让 service worker 控制的内容的子目录。在这个例子里,我们指定了 '/',表示 根网域下的所有内容。这也是默认值。
.register("./sw.js", { scope: "./" })
.then(function () {
console.log("Service Worker 注册成功");
});
// sw.js 负责做信息中转站
// 安装
/* 监听安装事件,install 事件一般是被用来设置你的浏览器的离线缓存逻辑 */
this.addEventListener("install", function (event) {
/* 通过这个方法可以防止缓存未完成,就关闭serviceWorker */
event.waitUntil(
/* 创建一个名叫V1的缓存版本 */
caches.open("v1").then(function (cache) {
/* 指定要缓存的内容,地址为相对于根域名的访问路径 */
return cache.addAll(["./index.html"]);
})
);
});
/* 注册fetch事件,拦截全站的请求 */
this.addEventListener("fetch", function (event) {
event.respondWith(
// magic goes here
/* 在缓存中匹配对应请求资源直接返回 */
caches.match(event.request);
);
});
// 激活
self.addEventListener("activate", (event) => {
event.waitUntil(
self.clients.matchAll().then((client) => {
client.postMessage({
msg: "Hey, from service worker! I'm listening to your fetch requests.",
source: "service-worker",
});
})
);
});
// A.html
navigator.serviceWorker.addEventListener("message", function (e) {
console.log(e.data);
});
// B.html
// 网页可以通过 navigator.serviceWorker.controller.postMessage API 向掌管自己的 SW 发送消息
navigator.serviceWorker.controller.postMessage("Hello A");
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
"Status Code:200 OK (from ServiceWorker)" in Chrome Network DevTools? (opens new window)
移除&unregister,参考 (opens new window)
移除&unregister,方法 1:
try {
self.addEventListener("install", function (e) {
self.skipWaiting();
});
self.addEventListener("activate", function (e) {
self.registration
.unregister()
.then(function () {
return self.clients.matchAll();
})
.then(function (clients) {
clients.forEach((client) => client.navigate(client.url));
});
});
} catch (e) {
console.log("close sw: ", e);
}
try {
if (window.navigator && navigator.serviceWorker) {
navigator.serviceWorker.getRegistrations().then(function (registrations) {
for (let registration of registrations) {
registration.unregister();
}
});
}
} catch (e) {
console.log("unregister sw: ", e);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
- 移除&unregister,方法 2:
chrome://serviceworker-internals找到对应的 sw 并关闭 - 移除&unregister,方法 3:
Open Developer Tools (F12) and Select Application. Then Either
Select Clear Storage -> Unregister service workerorSelect Service Workers -> Choose Update on Reload
# BroadcastChannel
仅在同源的上下文中有效。通过频道名称来进行独立通信,同一页面的两个 BroadcastChannel 对象是相互独立的。
// A.html
const channel = new BroadcastChannel("chat_channel");
document.getElementById("send").onclick = function () {
const message = document.getElementById("message").value;
channel.postMessage(message);
};
// B.html
const channel = new BroadcastChannel("chat_channel");
channel.onmessage = function (event) {
document.getElementById("output").innerText = event.data;
};
2
3
4
5
6
7
8
9
10
11
12
13
14
# B 页面意外崩溃,该如何通知 A 页面
可以利用 window 对象的 load 和 beforeunload 事件,通过心跳监控来获取 B 页面的崩溃。巧妙的利用了页面崩溃无法触发 beforeunload 事件来实现的。
- Service Worker 有自己独立的工作线程,与网页区分开,网页崩溃了,Service Worker 一般情况下不会崩溃;
- Service Worker 生命周期一般要比网页还要长,可以用来监控网页的状态;
- 网页可以通过 navigator.serviceWorker.controller.postMessage API 向掌管自己的 SW 发送消息
流程如下:
- B 页面加载后,通过 postMessage API 每 5s 给 sw 发送一个心跳,表示自己的在线,sw 将在线的网页登记下来,更新登记时间;
- B 页面在 beforeunload 时,通过 postMessage API 告知 sw 自己已经正常关闭,sw 将登记的网页清除;
- 如果 B 页面在运行的过程中 crash 了,sw 中的 running 状态将不会被清除,更新时间停留在崩溃前的最后一次心跳;
- A 页面 Service Worker 每 10s 查看一遍登记中的网页,发现登记时间已经超出了一定时间(比如 15s)即可判定该网页 crash 了。
// A.html
// 每 10s 检查一次,超过15s没有心跳则认为已经 crash
const CHECK_CRASH_INTERVAL = 10 * 1000;
const CRASH_THRESHOLD = 15 * 1000;
const pages = {};
let timer;
function checkCrash() {
const now = Date.now();
for (var id in pages) {
let page = pages[id];
if (now - page.t > CRASH_THRESHOLD) {
// 上报 crash
delete pages[id];
}
}
if (Object.keys(pages).length == 0) {
clearInterval(timer);
timer = null;
}
}
worker.addEventListener("message", (e) => {
const data = e.data;
if (data.type === "heartbeat") {
pages[data.id] = {
t: Date.now(),
};
if (!timer) {
timer = setInterval(function () {
checkCrash();
}, CHECK_CRASH_INTERVAL);
}
} else if (data.type === "unload") {
delete pages[data.id];
}
});
// B.html
if (navigator.serviceWorker.controller !== null) {
let HEARTBEAT_INTERVAL = 5 * 1000; // 每五秒发一次心跳
let sessionId = uuid(); // B页面会话的唯一 id
let heartbeat = function () {
navigator.serviceWorker.controller.postMessage({
type: "heartbeat",
id: sessionId,
data: {}, // 附加信息,如果页面 crash,上报的附加数据
});
};
window.addEventListener("beforeunload", function () {
navigator.serviceWorker.controller.postMessage({
type: "unload",
id: sessionId,
});
});
setInterval(heartbeat, HEARTBEAT_INTERVAL);
heartbeat();
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
# Chrome Capture Network Log
chrome://net-export/
# Proxy 与 Reflect
代理与反射的关系:简单来说,我们可以通过 Proxy 创建对于原始对象的代理对象,从而在代理对象中使用 Reflect 实现对 JavaScript 原始操作的拦截。
Proxy 代理,它内置了一系列”陷阱“用于创建一个对象的代理,从而实现基本操作的拦截和自定义(如属性查找、赋值、枚举、函数调用等)。
Reflect 反射,它提供拦截 JavaScript 操作的方法。这些方法与 Proxy 的方法相同。
const parent = {
get value() {
return "19Qingfeng";
},
};
const proxy = new Proxy(parent, {
// get中target表示原对象 key表示访问的属性名
get(target, key, receiver) {
console.log(receiver === proxy);
console.log(receiver === obj);
console.log(receiver === parent);
return target[key];
},
});
const obj = {
name: "wang.haoyu",
};
// 设置obj继承与parent的代理对象proxy
Object.setPrototypeOf(obj, proxy);
obj.value;
// false
// true
// false
// '19Qingfeng'
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
在 Proxy 中 getter 的 receiver 不仅仅会表示代理对象本身同时也还有可能表示继承于代理对象的对象,具体需要区别于调用方。
receiver: The reference to use as the this value in the getter function, if target[properKey] is an accessor property.
综上:Proxy 中 getter 的第三个参数 receiver 存在的意义就是为了正确的在 getter 中传递上下文,是为了传递正确的调用者指向。
PS:不要将 revceiver 和 getter 中的 this 弄混了,getter 中的 this 关键字表示的是代理的 handler 对象,也就是 Proxy 的第二个参数接收的对象。
你可以简单的将 Reflect.get(target, key, receiver) 理解成为 target[key].call(receiver),不过这是一段伪代码,但是这样你可能更好理解。
针对于 getter(当然 setter 其他之类涉及到 receiver 的同理):
- Proxy 中接受的 Receiver 形参表示代理对象本身或者继承于代理对象的对象。
- Reflect 中传递的 Receiver 实参表示修改执行原始操作时的 this 指向。
- 也就是说 Reflect 中的 receiver 参数相当于实际调用时触发 getter、setter 的对象的指针,有了它就可以得到期望的值。
# FastClick 原理
- 在 document.body 上绑定监听 touchstart 和 touchend 事件(touchstart touchend 会先于 click 事件触发)
- 监听 touchstart 事件记录当前点击元素 targetElement
- 监听 touchend 事件,使用自定义 DOM 事件模拟一个 click 事件,使用 targetElement.dispatchEvent 触发事件
- 把默认的 click 事件(300ms 之后触发)禁止掉
现代浏览器对 click 事件 300ms 延迟的处理方法:在meta标签中设置 viewport,并设置content='width=device-width'之后,就会取消掉 300ms 延时。
<meta name='viewport' content='width=device-width,initial-scale=1.0>
# token 和 cookie&session
# cookie
- http 是无状态的,所以增加了 cookie,每次请求时可以带上 cookie,以帮助服务端识别用户身份
- 服务端可以向客户端 set-cookie,cookie 大小限制 4kb
- 默认有跨域限制:不可跨域共享或跨域传递 cookie
# Set-Cookie 中的几个属性
- Expires 属性指定一个具体的到期时间,到了指定时间以后,浏览器就不再保留这个 Cookie。它的值是 UTC 格式。如果不设置该属性,或者设为 null,Cookie 只在当前会话(session)有效,浏览器窗口一旦关闭,当前 Session 结束,该 Cookie 就会被删除。另外,浏览器根据本地时间,决定 Cookie 是否过期,由于本地时间是不精确的,所以没有办法保证 Cookie 一定会在服务器指定的时间过期。
- Max-Age 属性指定从现在开始 Cookie 存在的秒数,比如
60 * 60 * 24 * 365(即一年)。过了这个时间以后,浏览器就不再保留这个 Cookie。如果同时指定了 Expires 和 Max-Age,那么 Max-Age 的值将优先生效。如果 Set-Cookie 字段没有指定 Expires 或 Max-Age 属性,那么这个 Cookie 就是 Session Cookie,即它只在本次对话存在,一旦用户关闭浏览器,浏览器就不会再保留这个 Cookie。 - Domain 属性指定浏览器发出 HTTP 请求时,哪些域名要附带这个 Cookie。如果没有指定该属性,浏览器会默认将其设为当前 URL 的一级域名,比如 www.example.com 会设为 example.com,而且以后如果访问 example.com 的任何子域名,HTTP 请求也会带上这个 Cookie。如果服务器在 Set-Cookie 字段指定的域名,不是当前域名或不属于当前域名的子域名,浏览器会拒绝这个 Cookie。
- Path 属性指定浏览器发出 HTTP 请求时,哪些路径要附带这个 Cookie。只要浏览器发现,Path 属性是 HTTP 请求路径的开头一部分,就会在头信息里面带上这个 Cookie。比如,PATH 属性是/,那么请求/docs 路径也会包含该 Cookie。当然,前提是域名必须一致。
- Secure 属性指定浏览器只有在加密协议 HTTPS 下,才能将这个 Cookie 发送到服务器。另一方面,如果当前协议是 HTTP,浏览器会自动忽略服务器发来的 Secure 属性。该属性只是一个开关,不需要指定值。如果通信是 HTTPS 协议,该开关自动打开。
- HttpOnly 属性指定该 Cookie 无法通过 JavaScript 脚本拿到,主要是 Document.cookie 属性、XMLHttpRequest 对象和 Request API 都拿不到该属性。这样就防止了该 Cookie 被脚本读到,只有浏览器发出 HTTP 请求时,才会带上该 Cookie。
- 现代浏览器开始禁止第三方 cookie:
- 和跨域限制不同,这里是禁止网页引入的第三方 js 设置 cookie
- 打击第三方广告,保护用户隐私
- 新增属性 SameSite:值可自己选择
- Strict:将阻止所有三方 Cookie 携带,这种设置基本可以阻止所有 CSRF 攻击,然而,它的友好性太差,即使是普通的 GET 请求它也不允许通过。
- Lax:只会阻止在使用危险 HTTP 方法进行请求携带的三方 Cookie,例如 POST 方式。同时,使用 JavaScript 脚本发起的请求也无法携带三方 Cookie。
- None:关闭/不启用
- First-Party Sets 策略:Chrome 新推出的,可以允许由同一实体拥有的不同关域名都被视为第一方。我们可以标记打算在同一方上下文共享 Cookie 的不同域名,目的是在防止第三方跨站点跟踪和仍然保持正常的业务场景下之间找到平衡。有一些限制:
- 一个集合可能只有一个所有者。
- 一个成员只能属于一个集合,不能重叠或混合。
- 域名列表不要过大。
- 新增属性 SameParty:就是为了配合 First-Party Sets 使用的;允许特定条件跨域共享 Cookie,所有开启了 First-Party Sets 域名下需要共享的 Cookie 都需要增加 SameParty 属性。在 SameParty 被广泛支持之前,你可以把它和 SameSite 属性一起定义来确保 Cookie 的行为降级,另外还有一些额外的要求:可以试用 --use-first-party-set 这个命令启动 Chrome ,就可以进行试用。
- SameParty Cookie 必须包含 Secure.
- SameParty Cookie 不得包含 SameSite=Strict.
# session
- cookie 用于登录验证,存储用户标识(如 userId)
- session 在服务端,存储用户详细信息,和 cookie 信息一一对应
- cookie+session 是常用的登录验证解决方案
# token
token 中可以存储用户信息、登录信息、有效期、使用限制等各种数据。
- cookie 是 HTTP 规范,而 token 是自定义传递
- cookie 会默认被浏览器存储,而 token 需自己存储
- token 默认没有跨域限制
- token 可以放在 request header 中传递,
Authorization: Bearer xxxxx
# 刷新 token
设置 access token 和 refresh token:
- access token:用来访问业务接口,由于有效期足够短,盗用风险小,也可以使请求方式更宽松灵活
- refresh token:用来获取 access token,有效期可以长一些,通过独立服务和严格的请求方式增加安全性;由于不常验证,也可以如前面的 session 一样处理
请求流程:
- 初次登录,POST 账号密码到认证服务,校验通过之后,生成 access token 和 refresh token,返回给客户端,客户端自行保存下来;
- access token 有效期内,请求接口时都只需带上 access token 即可;
- access token 过期之后,使用 refresh token 去认证服务校验 refresh token 是否在有效期;
- 如果 refresh token 仍在有效期,那么重新生成一个 access token 返回客户端,客户端使用新的 access token 去请求接口即可;
- 如果 refresh token 已过期,那么就重新登录。
# JWT - JSON Web Token
由 3 部分组成:header.payload.signature;
- 前端发起登录,后端验证成功后,返回一个加密 token
- 前端自行存储这个 token(其中包含了用户信息,加密了)
- 以后再访问服务端接口时,都带着这个 token,作为用户信息
# 综上
- cookie: HTTP 标准;跨域限制;配合 session 使用;
- token:无标准;无跨域限制;用于 JWT;
- session:
- 原理简单,易于学习
- 用户信息存储在服务端,可快速封禁某个用户
- 占用服务端内存,硬件成本高
- 多进程,多服务器时,不好同步--需使用第三方缓存,如 Redis
- 默认有跨域限制
- JWT:
- 不占用服务端内存
- 多进程,多服务器 不受影响
- 无跨域限制
- 用户信息存储在客户端,无法快速封禁某用户
- 万一服务端秘钥被泄露,则用户信息全部丢失
- token 体积一般大于 cookie,会增加请求的数据量
- session 和 token 的对比就是「用不用 cookie」和「后端存不存」的对比
# 怎么实现单点登录 SSO
设置 cookie 跨域共享
- 主域名/一级域名相同时,设置 cookie domain 为主域名,即可共享 cookie:
Set-Cookie:domain=.baidu.com;,之后请求后端时可以带上 cookie;
主域名完全不同,则 cookie 无法共享
- 可以使用 SSO 技术方案:有一个单独的第三方 SSO 服务,做专门的登录和信息保存、检验,例:有 A.com、B.com 和 SSO.com
- 用户进入 A 系统,没有登录凭证(ticket),A 系统给他跳到 SSO;
- SSO 没登录过,也就没有 sso 系统下没有凭证(注意这个和前面 A ticket 是两回事),输入账号密码登录
- SSO 账号密码验证成功,通过接口返回做两件事:一是种下 sso 系统下凭证(记录用户在 SSO 登录状态);二是下发一个 ticket
- 在 SSO 域下,SSO 不是通过接口把 ticket 直接返回,而是通过一个带 code 的 URL 重定向到系统 A 的接口上,这个接口通常在 A 向 SSO 注册时约定
- 浏览器被重定向到 A 域下,带着 code 访问了 A 的 callback 接口,callback 接口通过 code 换取 ticket
- 这个 code 不同于 ticket,code 是一次性的,暴露在 URL 中,只为了传一下换 ticket,换完就失效
- callback 接口拿到 ticket 后,在自己的域下 set cookie 成功,带着请求系统 A 接口
- 系统 A 校验 ticket,成功后正常处理业务请求
- 此时用户第一次进入系统 B,没有登录凭证(ticket),B 系统给他跳到 SSO
- SSO 登录过,系统下有凭证,不用再次登录,只需要跟上面一样,一个带 code 的 URL 重定向到系统 B 的接口上
- 然后浏览器被重定向到 B 域下,带着 code 访问了 B 的 callback 接口,callback 接口通过 code 换取 ticket
- 客户端拿到 ticket,保存起来,带着请求系统 B 接口
- OAuth2.0 使用第三方的登录验证,如 GitHub、微信扫码登录等等
# preload 和 prefetch
- preload 资源在当前页面使用,会优先加载,资源预获取。preload 也被称为预加载,其用于 link 标签中,可以指明哪些资源是在页面加载完成后即刻需要的,浏览器会在主渲染机制介入前预先加载这些资源,并不阻塞页面的初步渲染。
- prefetch 资源在未来页面使用,空闲时加载。 prefetch 则表示预提取,告诉浏览器加载下一页面可能会用到的资源,浏览器会利用空闲状态进行下载并将资源存储到缓存中。
- preload 的资源应该在当前页面立即使用,如果不加上 script 标签执行预加载的资源,控制台中会显示警告,提示预加载的资源在当前页面没有被引用;
- prefetch 的目的是取未来会使用的资源,所以当用户从 A 页面跳转到 B 页面时,进行中的 preload 的资源会被中断,而 prefetch 不会;
- 使用 preload 时,应配合 as 属性,表示该资源的优先级,使用
as="style"属性将获得最高的优先级,as="script"将获得低优先级或中优先级,其他可以取的值有font/image/audio/video; - preload 字体时要加上
crossorigin属性,即使没有跨域,否则会重复加载; - 这两种预加载资源不仅可以通过 HTML 标签设置,还可以通过 js 设置或 HTTP 响应头;
<link rel="preload" href="style.css" as="style" />
<link rel="preload" href="main.js" as="script" />
<link rel="prefetch" href="other.js" as="script" />
2
3
4
与 prefetch 指令相比,preload 指令有许多不同之处:
- preload chunk 会在父 chunk 加载时,以并行方式开始加载。prefetch chunk 会在父 chunk 加载结束后开始加载。
- preload chunk 具有中等优先级,并立即下载。prefetch chunk 在浏览器闲置时下载。
- preload chunk 会在父 chunk 中立即请求,用于当下时刻。prefetch chunk 会用于未来的某个时刻。
- 浏览器支持程度不同。
# dns-prefetch 和 preconnect
dns-prefetch即 DNS 预查询/预解析;preconnect即 DNS 预连接:在一个 HTTP 请求正式发给服务器前预先执行一些操作,这包括 DNS 解析,TLS 协商,TCP 握手;- DNS 查询通常使用 UDP 协议;
prerender:获取下个页面所有的资源,在空闲时渲染整个页面;
<link rel="dns-prefetch" href="https://fonts.google.com/" />
<link rel="preconnect" href="https://fonts.google.com/" as="script" crossorigin />
<link rel="prerender" href="https://fonts.google.com/" />
2
3
# meta 标签
meta 是文档级元数据元素,用来表示那些不能由其它 HTML 元相关元素(<base>、<link>, <script>、<style>或 <title>)之一表示的任何元数据。
- 如果设置了
name属性,meta 元素提供的是文档级别的元数据,应用于整个页面。 - 如果设置了
http-equiv属性,meta 元素则是编译指令,提供的信息与类似命名的 HTTP 头部相同。 - 如果设置了
charset属性,meta 元素是一个字符集声明,告诉文档使用哪种字符编码。 - 如果设置了
itemprop属性,meta 元素提供用户定义的元数据。
- name 属性: name 和 content 一起使用,前者表示要表示的元数据的名称,后者是元数据的值。
- 例:author、description、keywords、viewport
- robots:爬虫对此页面的处理行为
- renderer:指定双核浏览器的渲染方式
- http-equiv 属性: http-equiv 也是和 content 一起使用,前者表示要表示的元数据的名称,后者是元数据的值。http-equiv 所有允许的值都是特定 HTTP 头部的名称。
- 例:
<meta http-equiv='X-UA-Compatible' content='IE=edge,chrome=1' >用来是做 IE 浏览器适配(IE8-IE11)。 - 如果在我们的 http 头部中也设置了这个属性,并且和 meta 中设置的有冲突,那么哪一个优先呢?答案是:开发者偏好(meta 元素)优先于 Web 服务器设置(HTTP 头)。
content-type:用来声明文档类型和字符集x-dns-prefetch-control:一般来说,HTML 页面中的 a 标签会自动启用 DNS 提前解析来提升网站性能,但是在使用 https 协议的网站中失效了,此时用这个属性打开 dns 对 a 标签的提前解析cache-control、Pragma、Expires:和缓存相关的设置,但是遗憾的是这些往往不生效,我们一般都通过 http headers 来设置缓存策略
- 例:
# 我们日常接触最频繁的前端工程化工具:
- Loader: 因为前端项目中包含各种文件类型和数据, 需要将其进行相应的转换变成 JS 模块才能为打包工具使用并进行构建. JS 的 Compiler 和其他类型文件的 Loader 可以统称为 Transfomer.
- Plugin: 可以更一步定制化构建流程, 对模块进行改造(比如压缩 JS 的 Terser)
- 还有一些前端构建工具是基于通用构建工具进行了一定封装或者增加额外功能的, 比如 CRA/Jupiter/Vite/Umi
- Task Runner 任务运行器: 开发者设置脚本让构建工具完成开发、构建、部署中的一系列任务, 大家日常常用的是 npm/yarn 的脚本功能; 在更早一些时候, 比较流行 Gulp/Grunt 这样的工具
- Package Manager 包管理器: 这个大家都不会陌生, npm/Yarn/pnmp 帮开发者下载并管理好依赖, 对于现在的前端开发来说必不可少.
- Compiler/Transpiler 编译器: 在市场上很多浏览器还只支持 ES5 语法的时候, Babel 这样的 Comipler 在前端开发中必不可少; 如果你是用 TypeScript 的话, 也需要通过 tsc 或者 ts-loader 进行编译.
- Bundler 打包工具: 从开发者设置的入口出发, 分析模块依赖, 加载并将各类资源最终打包成 1 个或多个文件的工具.
# 响应式图片
- 使用 img 的 srcset 属性:
- tips:srcset 和 sizes 要放到 src 之前,否则 Safari 会先解析 src 导致产生不必要的请求。
<!-- 根据dpr选择图片 -->
<img srcset="image.jpg, image_2x.jpg 2x, image_3x.jpg 3x" src="image.png" />
<!-- 根据需要选择图片 -->
<img srcset="image_S.jpg 600w, image_M.jpg 900w, image_L.jpg 1500w, image_XL.jpg 3000w" src="image.png" />
<!-- 借助sizes实现更精细的控制 -->
<img
srcset="image_S.jpg 600w, image_M.jpg 900w, image_L.jpg 1500w, image_XL.jpg 3000w"
sizes="(max-width:450px) 100vw,(max-width:900px) 50vw,(max-width:1300px) 33vw, 300px"
src="image.png" />
2
3
4
5
6
7
8
9
10
# 适配 iPhone 的齐刘海
- 设置
viewport-fit:cover; - 预定义变量:
safe-area-inset-left、safe-area-inset-right、safe-area-inset-top、safe-area-inset-bottom - 设置样式
padding-top:env(safe-area-inset-top);padding-top:constant(safe-area-inset-top); - Taro 小程序中直接使用 3 即可
# 滚动穿透
表现:在滚动弹出框的内容时,弹框下的可滚动元素也会跟着滚动。
scroll 事件特性:
- 不会冒泡,所以无法阻止默认行为;
- 如果当前节点是不能滚动的,那么将尝试 document 上的滚动;
解决方案:打开弹窗的时候禁用外层页面滚动
在 body 上设置
overflow: hidden;缺点:兼容性问题在 body 上设置
position:fixed;height:100%;width:100%;,缺点:外层页面不会停留在原来的位置而是被置顶。需记录下 scrollTop 的位置,然后通过scrollTop(0,scrollTop)恢复在 body 上设置
position:fixed;height:100%;width:100%;;在 body 下的 div 上使用自己的height:100%;overflow:auto/scroll;touch-action: 默认情况下,平移(滚动)和缩放手势由浏览器专门处理,但是可以通过 CSS 特性touch-action来改变触摸手势的行为。在 popup 元素上设置该属性,禁用元素(及其不可滚动的后代)上的所有手势就可以解决该问题了。touch-action: none;(小程序本身好像就不可以缩放)值 描述 auto 启用浏览器处理所有平移和缩放手势。 none 禁用浏览器处理所有平移和缩放手势。 manipulation 启用平移和缩放手势,但禁用其他非标准手势,例如双击缩放。 pinch-zoom 启用页面的多指平移和缩放。 event.preventDefault: 在touchstart和touchmove事件中调用preventDefault方法可以阻止任何关联事件的默认行为,包括鼠标事件和滚动。- Step 1. 监听弹窗最外层元素(popup)的 touchmove 事件并阻止默认行为来禁用所有滚动(包括弹窗内部的滚动元素)。
- Step 2. 释放弹窗内的滚动元素,允许其滚动:同样监听 touchmove 事件,但是阻止该滚动元素的冒泡行为(stopPropagation),使得在滚动的时候最外层元素(popup)无法接收到 touchmove 事件。
# 滚动溢出
表现:弹窗内含有滚动元素,在滚动元素滚到底部或顶部时,再往下或往上滚动,也会触发页面的滚动,这种现象称之为滚动链(scroll chaining), 但是感觉滚动溢出(overscroll)这个名字更言辞达意。
解决方案:
overscroll-behavior: 是 CSS 的一个特性,允许控制浏览器滚动到边界的表现。overscroll-behavior: none;,缺点是不支持 safari。
值 描述 auto 默认效果,元素的滚动可以传播到祖先元素。 contain 阻止滚动链,滚动不会传播到祖先元素,但是会显示节点自身的局部效果。例如 Android 上过度滚动的发光效果或 iOS 上的橡皮筋效果。 none 与 contain 相同,但是会阻止自身的过度效果。 event.preventDefault: 当组件滚动到底部或顶部时,通过调用event.preventDefault阻止所有滚动,从而页面滚动也不会触发了,而在滚动之间则不做处理。
let initialPageY = 0;
scrollBox.addEventListener("touchstart", (e) => {
initialPageY = e.changedTouches[0].pageY;
});
scrollBox.addEventListener("touchmove", (e) => {
const deltaY = e.changedTouches[0].pageY - initialPageY;
// 禁止向上滚动溢出
if (e.cancelable && deltaY > 0 && scrollBox.scrollTop <= 0) {
e.preventDefault();
}
// 禁止向下滚动溢出
if (e.cancelable && deltaY < 0 && scrollBox.scrollTop + scrollBox.clientHeight >= scrollBox.scrollHeight) {
e.preventDefault();
}
});
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# App 唤起
# URL Scheme
URL Scheme:把页面地址的协议 http/https 换成自己的 scheme 协议,通过 a 标签或者 location.href 跳转,Native 解析 url 参数打开对应页面,监听 visibilitychange 事件并使用定时延时 2.5 左右判断是否唤起成功,否则执行下载 App 操作。
- 原理:安卓在 manifest 里通过 intent-filter 配置,苹果在 info.plist 里添加 URL types 来注册一个 scheme
- 优点:兼容性好,无论安卓或者 iOS 都能支持,是目前最常用的方式
- 缺点:
- 无法准确判断是否唤起成功,因为本质上这种方式就是打开一个链接,并且还不是普通的 http 链接,所以如果用户没有安装对应的 APP,那么尝试跳转后在浏览器中会没有任何反应,甚至在一些 webview 里还会跳到一个类似「无法打开 taobao://xxxx」这样的错误页或者错误弹框,体验不够好;
- 在很多浏览器和 webview 中会有一个弹窗提示你是否打开对应 APP,可能会导致用户流失;
- 有 URL Scheme 劫持风险,比如某不知名 app 也向系统注册了 taobao:// 这个 scheme ,唤起流量可能就会被劫持到这个 app 里;
- 很容易被屏蔽,app 很轻松就可以拦截掉通过 URL Scheme 发起的跳转。
# Universal Links
Universal Links(iOS 9+),可以直接通过 https 协议的链接来打开 APP,如果没有安装则打开对应 H5 页面。例:<a href="https://b.mashort.cn/">打开手淘</a>
- 原理:
- 在 APP 中注册自己要支持的域名;
- 在自己域名的根目录下配置一个 apple-app-site-associatio 文件即可。
- 优点:
- 相对 URL Scheme,universal links 有一个较大优点是它唤端时没有弹窗提示,可减少一部分流失;
- 对于没有安装应用的用户,点击链接就会直接打开对应的页面,那么我们也可以对这种情况做统一的处理,比如引导到一个中转页,也能一定程度解决 URL Scheme 无法准确判断唤端失败的问题;
- 缺点:
- 只能在 iOS 上用;
- 只能由用户主动触发,比如用浏览器扫码打开页面,就没有办法由页面直接唤起 APP,而需要用户手动点击页面按钮才能唤起;
# 微信开放标签
微信开放标签wx-open-launch-app,需要一个公众平台的服务号和一个开放平台的账号以及应用进行绑定,通过腾讯应用宝打开 App
# H5 唤端兼容
不管是 URL Scheme 还是 universal links,其本质上都是打开一个 URL,在 H5 中有几种实现方式:
- iframe:最常采用的方式是使用 iframe 来做跳转, 方法是动态插入一个隐藏的 iframe,在 iframe onload 之后就会触发唤起,这样的好处是即便用户没有安装应用,当前页面也不会跳转到错误的页面。
iframe = document.createElement("iframe");
iframe.frameborder = "0";
iframe.style.cssText = "display:none;border:0;width:0;height:0;";
document.body.appendChild(iframe);
iframe.src = "taobao://m.taobao.com";
2
3
4
5
- a 标签:在 iOS 9 以上的 safari 中,不支持 iframe 唤起,可以用生成 a 标签并模拟点击的方式。
var a = document.createElement("a");
a.setAttribute("href", url);
a.style.display = "none";
document.body.appendChild(a);
var e = document.createEvent("HTMLEvents");
e.initEvent("click", false, false);
a.dispatchEvent(e);
2
3
4
5
6
7
8
- window.location:对于 intent 和 universal links 可以直接使用设置 window.location.href 的方式跳转,因为如果没有安装 app 他们也不会跳到错误的页面。这三种方式基本可以兼容所有的浏览器。
# 判断是否唤起成功
不管哪种唤起方式,目前在 H5 页面中都没有办法直接知道是否唤起成功。这也很好理解,唤端本身就是打开一个 URL,即使我们通过 a 标签打开的是一个正常的 http 的链接,作为页面本身同样也无法得知页面是否加载成功。不过我们可以通过一些其他的办法间接的去判断,主要是利用成功唤起后,当前的 H5 页面会被切到后台这一特性:在触发唤起后,监听 n 秒内是否触发了 blur 或者 visibilitychange 事件,有触发并且 document.hidden 为 true 说明可能是唤起成功(当然也有可能是用户自己切走了);
const timer = window.setTimeout(() => {
// 失败回调
}, 3000);
const successHandler = () => {
if (document.hidden) {
window.clearTimeout(timer);
}
};
window.addEventListener("blur", successHandler, { once: true });
window.addEventListener("visibilitychange", successHandler, { once: true });
2
3
4
5
6
7
8
9
10
11
# 下载还原
实际业务中,通常会希望用户在唤端失败后跳转到到 app 下载页,以继续引导用户进端,但下载一般是通过跳转到应用商店或者直接拉起下载 APK 包,期间是没有办法给安装包传递参数的,所以用户安装好 app 后也不能继续在端内还原下载之前的页面。为了让用户可以在安装 app 之后继续还原之前的链路,尽可能的减少流失,我们实现了一套「口令还原」的协议:
- 在用户点击下载时,把希望在安装后打开的链接按协议约定的格式写入到剪贴板中;
- 用户安装 app 并首次激活时,进入端内如果取出来的是约定好的「还原口令」,则根据口令打开对应的页面。 通过这种方式,即便用户唤端失败,也可能最后能进到端内的承接页,一定程度上把原本在下载 app 后无法继续承接的用户捞了回来。
缺点:
- 写到剪贴板的口令可能会被劫持,所以端内目前只支持在白名单里的链接进行还原;
- 如果剪贴板中的口令被覆盖,依然没法还原成功;
- 用户安装后首次打开 app 时会有很多初始化的加载,此时打开承接页会使得整体性能表现更差;
- 如果是比较习惯用剪贴板的用户,这个方式无疑污染了用户的剪贴板;
- 浏览器限制前端写剪贴板的动作只能在用户触发的同步事件中触发。
# picture 标签
HTML <picture> 元素通过包含零或多个 <source> 元素和一个 <img> 元素来为不同的显示/设备场景提供图像版本。浏览器会选择最匹配的子 <source> 元素,如果没有匹配的,就选择 <img> 元素的 src 属性中的 URL。然后,所选图像呈现在<img>元素占据的空间中。对于不支持<picture> 的浏览器,也只是相当于<img> 外面套了一层<div>,不会影响展示。
<!-- data-thumbnail是自定义属性 -->
<picture>
<source srcset="/media/cc0-images/surfer-240-200.jpg" media="(min-width: 600px)" />
<source srcset="/media/cc0-images/surfer-240-400.jpg" media="(min-width: 1200px)" />
<img
data-thumbnail="data:image/jpeg;base64,PNNAABCFGHJ4678VBD..."
src="/media/cc0-images/painted-hand-298-332.jpg"
alt="" />
</picture>
2
3
4
5
6
7
8
9
- img 中的 alt:属性包含一条对图像的文本描述,这不是强制性的,但对可访问性而言,它难以置信地有用——屏幕阅读器会将这些描述读给需要使用阅读器的使用者听,让他们知道图像的含义。如果由于某种原因无法加载图像,普通浏览器也会在页面上显示 alt 属性中的备用文本:例如,网络错误、内容被屏蔽或链接过期时。
# Fragment 文档碎片
const fragment = document.createDocumentFragment();...;fragment.appendChild(div);...;container.appendChild(fragment);,好处:
- 之前都是每次创建一个 div 标签就 appendChild 一次,但是有了文档碎片可以先把 1 页的 div 标签先放进文档碎片中,然后一次性 appendChild 到 container 中,这样减少了 appendChild 的次数,极大提高了性能;
- 页面只会渲染文档碎片包裹着的元素,而不会渲染文档碎片
# getBoundingClientRect
包含如下属性:
- x:DOMRect 原点的 x 坐标。
- y:DOMRect 原点的 y 坐标。
- width:DOMRect 的宽度。
- height:DOMRect 的高度。(视口高度,不包括工具栏)
- top:返回 DOMRect 的顶坐标值(与 y 具有相同的值,如果 height 为负值,则为 y + height 的值)。
- bottom:返回 DOMRect 的底坐标值(与 y + height 具有相同的值,如果 height 为负值,则为 y 的值)。
- left:返回 DOMRect 的左坐标值(与 x 具有相同的值,如果 width 为负值,则为 x + width 的值)。
- right:返回 DOMRect 的右坐标值(与 x + width 具有相同的值,如果 width 为负值,则为 x 的值)。
const domRect:DOMRect = myElement.getBoundingClientRect();方法返回元素的大小及其相对于视口的位置。- 返回值是一个 DOMRect 对象,这个对象是由该元素的 getClientRects() 方法返回的一组矩形的集合,就是该元素的 CSS 边框大小。
- 返回的结果是包含完整元素的最小矩形,并且拥有 left, top, right, bottom, x, y, width, 和 height 这几个以像素为单位的只读属性用于描述整个边框。
- 除了 width 和 height 以外的属性都是相对于视图窗口的左上角(0,0)来计算的。
如果是标准盒子模型,元素的尺寸等于
width/height + padding + border-width的总和。如果box-sizing: border-box,元素的的尺寸等于width/height。- 当滚动位置发生了改变,top 和 left 属性值就会随之立即发生变化(因此,它们的值是相对于视口的,而不是绝对的)。
- 如果你需要获得相对于整个网页左上角定位的属性值,那么只要给 top、left 属性值加上当前的滚动位置(通过 window.scrollX 和 window.scrollY),这样就可以获取与当前的滚动位置无关的值。
- 如果需要更好的跨浏览器兼容性,请使用 window.pageXOffset 和 window.pageYOffset 代替 window.scrollX 和 window.scrollY。
# SSR 服务端渲染
# 优点
- 无首屏等待,首屏直出
- 方便 SEO 优化
- 生成完整的 HTML 字符串,方便缓存及生成静态化文件
- 减少请求次数,减轻服务器压力
# 缺点
- 服务端需要做复杂的处理逻辑,且同构的过程需要服务端和客户端都执行一遍代码,消耗大量服务端资源
- 页面的加载都需要向服务器请求完整的页面内容
- 学习开发维护成本较高
# React 提供的服务端渲染 api
- ReactDOMServer.renderToString(element)
- ReactDOM.hydrate(element,container)
- renderToNodeStream/renderToString 对最终的渲染结果没区别,前者性能要好得多,因为组件渲染为字符串,是一次性处理完之后才开始向浏览器端返回结果,而采用流的话可以边读边输出,可以让页面更快的展现,缩短首屏展示时间。
- 发起请求到渲染流程:
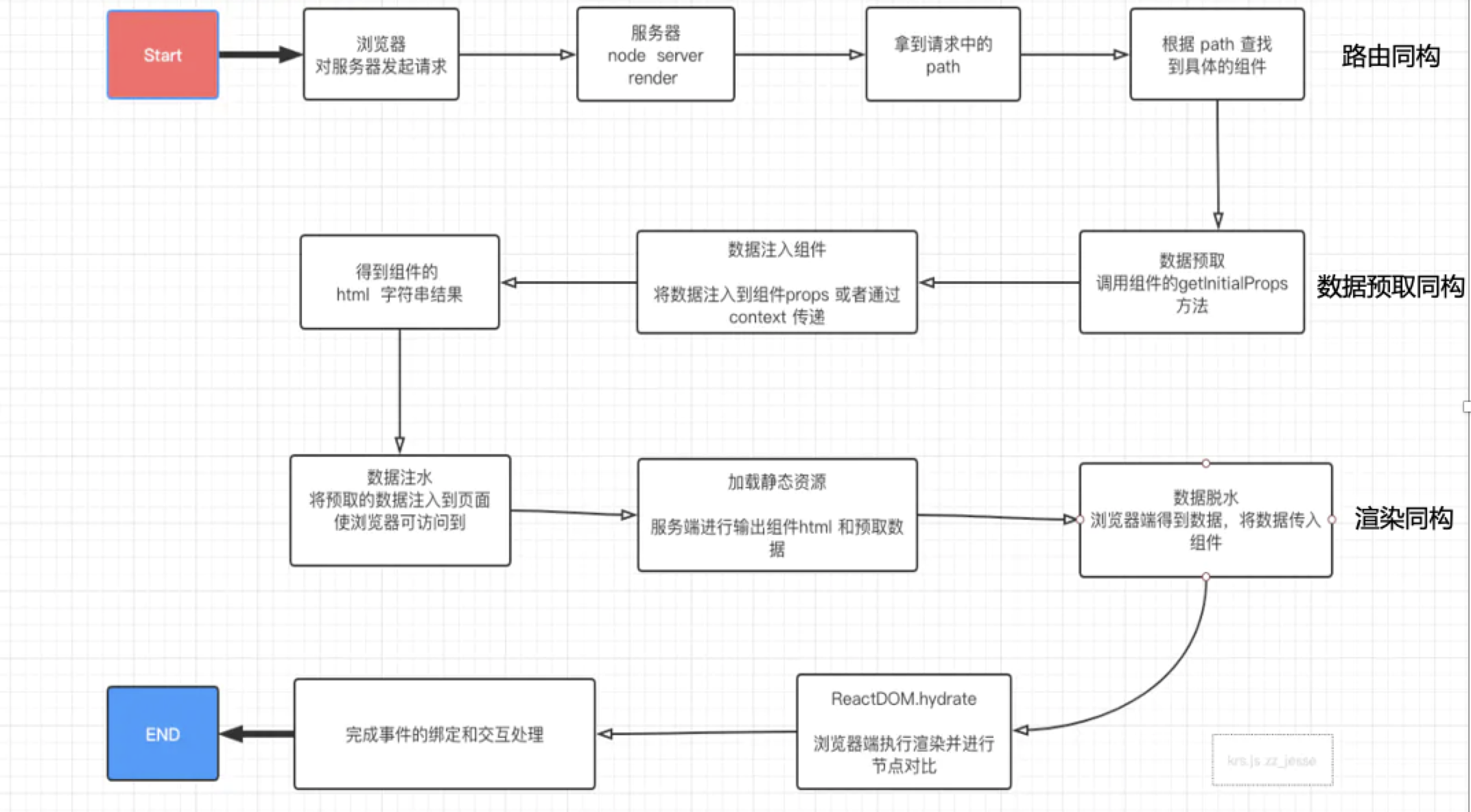
- 从图中可以看出:同一份代码需要运行两次,一次在服务端渲染完成页面结构,一次在客户端渲染完成事件绑定。
- 所谓同构就是采用一套代码,构建双端逻辑,最大限度重用代码,不需维护两套代码。
- 还有一个重要特性也是同构的重要体现:浏览器接管页面后的进一步渲染(交互、事件)过程中,会判断已有的 DOM 结构和浏览器渲染出的结构是否相同,若相同则不重复渲染,只需绑定事件即可。该特性是 react 提供的双端节点对比功能。
# 同构
# 路由同构
- 双端共用一套路由表、集中式路由配置(因为服务端渲染时需要根据 path 去找对应的组件)
- StaticRouter、express.Router()、约定式路由(next.js)、动态路由需要正则匹配(pathToRegexp、reac-router 的 matchPath 方法)
- 路由分割、按需渲染 import()
# 数据预取同构
- 双端都支持的请求 api axios
- 组件的静态方法 Component.getInitialProps
- 在 renderToString 前预取数据,并作为 props 传入组件
# 渲染同构
- 数据注水
- 数据脱水
# 缓存及静态文件原理
- 静态文件优化
- 不需要预取数据的页面
- CDN
- 页面缓存
- url 作为 key,html 字符串作为 key
- redis
# 双端差异对比
| 服务端 | 客户端 | 解决方案 | |
|---|---|---|---|
| window | [X] | [Y] | 判断环境 |
| document | [X] | [Y] | jsdom |
| fetch | [X] | [Y] | axios |
| useEffect | [X] | [Y] | getInitialProps |
| styled-components | [Y] | [Y] | ssr 配置 |
# 虚拟列表
超多条数据渲染时,一般的解决方案有:前/后端分页、触底加载、懒加载、虚拟列表等。
虚拟列表的概念:虚拟滚动,就是根据容器可视区域的列表容积数量,监听用户滑动或滚动事件,动态截取长列表数据中的部分数据渲染到页面上,动态使用空白站位填充容器上下滚动区域内容,模拟实现原生滚动效果。
基本实现
- 可视区域的高度
- 列表项的高度
- 可视区域能展示的列表项个数 = ~~(可视区域高度 / 列表项高度) + 2
- 开始索引
- 结束索引
- 预加载(防止滚动过快,造成暂时白屏)
- 根据开始索引和结束索引,截取数据展示在可视区域
- 滚动节流
- 上下空白区使用 padding 实现
- 滑动到底,再次请求数据并拼接
# JS Bridge
# 什么是 JSBridge
JSBridge 是一种 webview 侧和 native 侧进行通信的手段,webview 可以通过 jsb 调用 native 的能力,native 也可以通过 jsb 在 webview 上执行一些逻辑。
JSBridge 简单来讲,主要是 给 JavaScript 提供调用 Native 功能的接口,让混合开发中的『前端部分』可以方便地使用地址位置、摄像头甚至支付等 Native 功能。
# JSBridge 的实现方式 1
在比较流行的 JSBridge 中,主要是通过拦截 URL 请求来达到 native 端和 webview 端相互通信的效果的。以比较火的 WebviewJavascriptBridge 为例,来解析一下它的实现方式。
拦截 URL SCHEME 的主要流程是:h5 端通过某种方式(例如 iframe.src)发送 URL Scheme 请求,之后 Native 拦截到请求并根据 URL SCHEME(包括所带的参数)进行相关操作。
缺陷:
- 使用 iframe.src 发送 URL SCHEME 会有 url 长度的隐患。
- 创建请求,需要一定的耗时,比注入 API 的方式调用同样的功能,耗时会较长。
有些方案为了规避 url 长度隐患的缺陷,在 iOS 上采用了使用 Ajax 发送同域请求的方式,并将参数放到 head 或 body 里。这样,虽然规避了 url 长度的隐患,但是 WKWebView 并不支持这样的方式。
# 1.在 native 端和 webview 端注册 Bridge
注册的时候,需要在 webview 侧和 native 侧分别注册 jsbridge,其实就是用一个对象把所有函数储存起来。
# 2.在 webview 里面注入初始化代码
主要做了以下几件事:
- 创建一个名为 WVJBCallbacks 的数组,将传入的 callback 参数放到数组内
- 创建一个 iframe,设置不可见,设置 src 为
https://__bridge_loaded__ - 设置定时器移除这个 iframe
# 3.在 native 端监听 URL 请求
iOS 中有两种 webview,一种是 UIWebview,另一种是 WKWebview,这里以 WKWebview 为例:
- 拦截了所有的 URL 请求并拿到 url
- 首先判断 isWebViewJavascriptBridgeURL,判断这个 url 是不是 webview 的 iframe 触发的,具体可以通过 host 去判断
- 继续判断,如果是 isBridgeLoadedURL,那么会执行 injectJavascriptFile 方法,会向 webview 中再次注入一些逻辑,其中最重要的逻辑就是,在 window 对象上挂载一些全局变量和 WebViewJavascriptBridge 属性
- 继续判断,如果是 isQueueMessageURL,那么这就是个处理消息的回调,需要执行一些消息处理的方法
# 4.webview 调用 native 能力
- webview 侧 callHandler
- 当 webview 调用 native 时,会调用 callHandler 方法:实际上就是先生成一个 message,然后 push 到 sendMessageQueue 里,然后更改 iframe 的 src。
- native 侧 flushMessageQueue
- 然后,当 native 端检测到 iframe src 的变化时,会走到 isQueueMessageURL 的判断逻辑,然后执行 WKFlushMessageQueue 函数,获取到 JS 侧的 sendMessageQueue 中的所有 message。
- 当一个 message 结构存在 responseId 的时候说明这个 message 是执行 bridge 后传回的。
- 取不到 responseId 说明是第一次调用 bridge 传过来的,这个时候会生成一个返回给调用方的 message,其 reponseId 是传过来的 message 的 callbackId,当 native 执行 responseCallback 时,会触发_dispatchMessage 方法执行 webview 环境的的 js 逻辑,将生成的包含 responseId 的 message 返回给 webview。
- webview 侧 handleMessageFromObjC
- 如果从 native 获取到的 message 中有 responseId,说明这个 message 是 JS 调 Native 之后回调接收的 message,所以从一开始 sendData 中添加的 responseCallbacks 中根据 responseId(一开始存的时候是用的 callbackId,两个值是相同的)取出这个回调函数并执行,这样就完成了一次 JS 调用 Native 的流程。
- 过程总结,如图:
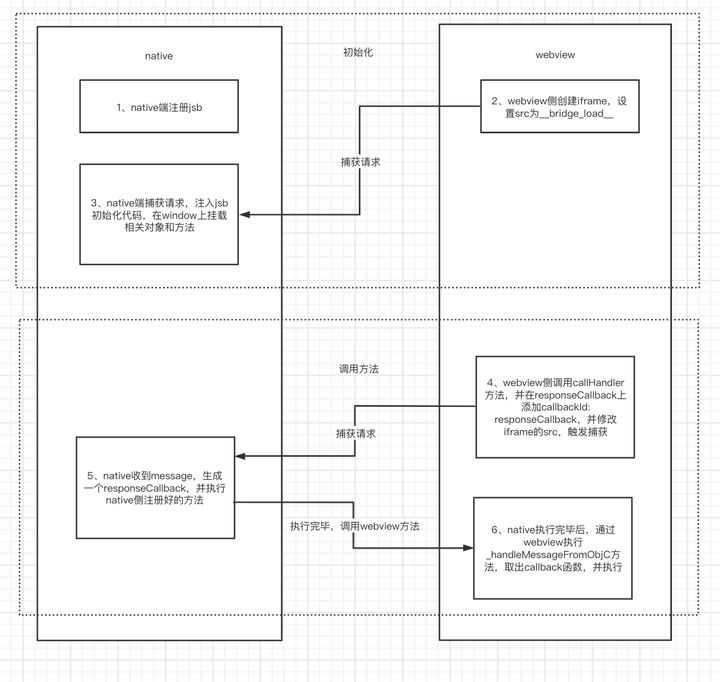
- native 端注册 jsb
- webview 侧创建 iframe,设置 src 为
__bridge_load__ - native 端捕获请求,注入 jsb 初始化代码,在 window 上挂载相关对象和方法
- webview 侧调用 callHandler 方法,并在 responseCallback 上添加 callbackId: responseCallback,并修改 iframe 的 src,触发捕获
- native 收到 message,生成一个 responseCallback,并执行 native 侧注册好的方法
- native 执行完毕后,通过 webview 执行_handleMessageFromObjC 方法,取出 callback 函数,并执行
# 5.native 调用 webview 能力
native 调用 webview 注册的 jsb 的逻辑是相似的,不过就不是通过触发 iframe 的 src 触发执行的了,因为 Native 可以自己主动调用 JS 侧的方法。毕竟不管是 iOS 的 UIWebView 还是 WKWebView,还是 Android 的 WebView 组件,都以子组件的形式存在于 View/Activity 中,直接调用相应的 API 即可。其具体过程如图: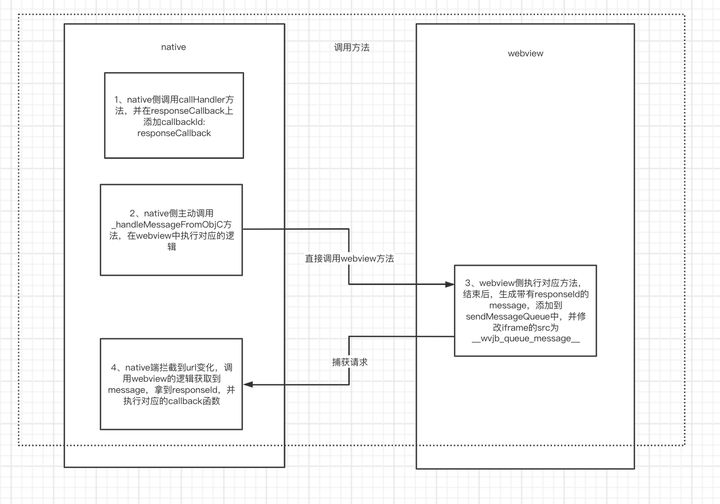
Native 调用 JavaScript,其实就是执行拼接 JavaScript 字符串,从外部调用 JavaScript 中的方法,因此 JavaScript 的方法必须在全局的 window 上。
- native 侧调用 callHandler 方法,并在 responseCallback 上添加 callbackId: responseCallback
- native 侧主动调用_handleMessageFromObjC 方法,在 webview 中执行对应的逻辑
- webview 侧执行结束后,生成带有 responseId 的 message,添加到 sendMessageQueue 中,并修改 iframe 的 src 为
__wvjb_queue_message__ - native 端拦截到 url 变化,调用 webview 的逻辑获取到 message,拿到 responseId,并执行对应的 callback 函数
- Q:为什么选择 iframe.src 不选择 locaiton.href ?因为如果通过 location.href 连续调用 Native,很容易丢失一些调用。
- 对于 Android,在 Kitkat(4.4)之前并没有提供 iOS 类似的调用方式,只能用 loadUrl 一段 JavaScript 代码,来实现:
webView.loadUrl("javascript:" + javaScriptString); - Kitkat 之后的版本,也可以用
evaluateJavascript方法实现:webView.evaluateJavascript(javaScriptString, new ValueCallback<String>() {..} - 但是使用 loadUrl 的方式,并不能获取 JavaScript 执行后的结果。
# JSBridge 的实现方式 2
- DSBridge
- 借助 WebView.addJavascriptInterface 实现 H5 与 Native 通信。在安卓 4.2 之前,Android 注入 JavaScript 对象的接口是
addJavascriptInterface,但是这个接口有漏洞,可以被不法分子利用,危害用户的安全,因此在安卓 4.2 中引入新的接口@JavascriptInterface,替代这个接口,解决安全问题。- 声明一个 class:
JavaScriptInterface,有 postMessage 等方法 - 在 onCreate 方法中生成一个实例
final JavaScriptInterface myJavaScriptInterface = new JavaScriptInterface(this) Webview.getSettings().setJavaScriptEnabled(true);Webview.addJavascriptInterface(myJavaScriptInterface, "nativeBridge");- h5 调用:
window.nativeBridge.postMessage(message);
- 声明一个 class:
- 通过 prompt 实现 H5 与 Native 的通信(安卓 4.2 之前很多方案都采用拦截 prompt 的方式来实现)
# JSBridge 注入失败怎么处理
- 方法一
- 再返回至 H5 页面时点击调用 window.location.reload()方法
- app 端去抓取 reload()方法
- 调用 app 的 reload 方法(销毁原有 webView ,创建新的 webView 注入 JsBridge)
- 方法二
- jsBridge 提供 reload 方法(做的事件就是 reload 整个 webView,即上面说的 ios 自刷新的功能)
- 在返回至 H5 页面时 点击调用 jsBridge.reload()方法
# 总结
- JavaScript 调用 Native 的方式,主要有两种:注入 API 和 拦截 URL SCHEME。
- 注入 API 方式的主要原理是,通过 WebView 提供的接口,向 JavaScript 的 Context(window)中注入对象或者方法,让 JavaScript 调用时,直接执行相应的 Native 代码逻辑,达到 JavaScript 调用 Native 的目的。
- 拦截 URL SCHEME 的主要流程是:Web 端通过某种方式(例如 iframe.src)发送 URL Scheme 请求,之后 Native 拦截到请求并根据 URL SCHEME(包括所带的参数)进行相关操作。
- 相比于 JavaScript 调用 Native, Native 调用 JavaScript 较为简单,毕竟不管是 iOS 的 UIWebView 还是 WKWebView,还是 Android 的 WebView 组件,都以子组件的形式存在于 View/Activity 中,直接调用相应的 API 即可。
- Native 调用 JavaScript,其实就是执行拼接 JavaScript 字符串,从外部调用 JavaScript 中的方法,因此 JavaScript 的方法必须在全局的 window 上。(闭包里的方法,JavaScript 自己都调用不了,更不用想让 Native 去调用了)。
- 对于 JSBridge 的引用,常用有两种方式,各有利弊。
- 由 Native 端进行注入。注入方式和 Native 调用 JavaScript 类似,直接执行 JSBridge 的全部代码。
- 优点:JSBridge 的版本很容易与 Native 保持一致,Native 端不用对不同版本的 JSBridge 进行兼容;
- 缺点:注入时机不确定,需要实现注入失败后重试的机制,保证注入的成功率,同时 JavaScript 端在调用接口时,需要优先判断 JSBridge 是否已经注入成功。
- 由 JavaScript 端引用。直接与 JavaScript 一起执行。
- 优点:JavaScript 端可以确定 JSBridge 的存在,直接调用即可;
- 缺点:如果 JSBridge 的实现方式有更改,JSBridge 需要兼容多版本的 Native Bridge 或者 Native Bridge 兼容多版本的 JSBridge。
# 二者互相调用
- Android 调用 JS:
H5 将 JSBridge 绑定在 window 上,Native 通过原生方法调用这个对象上的 H5 接收方法。因为原生可以直接拿到 webview 实例。
webview.loadUrl("javascript:function()"):android4.4 及以下的版本,通过 webview.loadUrl("javascript:alert('hello world')""),可以在 android 平台将 js 代码注入到 html 页面,loadUrl 方法可以直接调用 js 中定义的函数,也可以把 android 本地的 assets 目录下的 js 文件以字符串的形式注入到 html 页面中,但是这个注入时机一定要等到 html 页面加载完毕才能做,即在 WebViewClient.onPageFinished 的回调函数中调用,这样就相当于在 html 页面中直接引用了 js 资源文件。对于客户端来说,java 调用 js 本质上是一个拼接 js 字符串的过程,但是调用 loadUrl 不能直接获取 js 函数的返回值。webview.evaluateJavaScript("javascript:JSBridge.onFinish(port,jsonObj);"):可以获取 js 函数的返回值,该方法只有在 android4.4 及以上的版本才可以使用。其他用法和 loadUrl 一致。
- JS 调用 Android:
- 对象映射:
通过webview.addJavascriptInterface(new JSObject(),'javaObject'),这样可以js代码中可以直接调用javaObject对象,从而实现JS调用Java的功能,即原生将 WebViewJavascriptBridge 绑定在 window 上,H5 直接调用这个对象中的原生接收方法。 - URL 拦截:
在html页面通过iframe.src、window.open、documention.location或者href,这四种方法都可以在html页面中打开一个连接,从而会触发Java中的WebViewClient.shouldOverrideUrlLoading方法 - JS 方法拦截:
在JS中调用alert、console、prompt、confirm等方法就会触发WebChromeClient的onJsAlert、onConsoleMessage、onJsPrompt、onJsConfirm方法的回调。
推荐:
- JavaScript 调用 Native 推荐使用 注入 API 的方式(iOS6 忽略,Android 4.2 以下使用 WebViewClient 的 onJsPrompt 方式)。
- Native 调用 JavaScript 则直接执行拼接好的 JavaScript 代码即可。
- 知识点:在 Android 平台上要实现 Native 和 JS 的通信主要通过 WebViewClient 和 WebChromeClient 两个类来实现。
- WebViewClient 的作用是帮助 WebView 处理各种通知、事件请求,其主要的方法有:onLoadResource、onPageStart、onPageFinished、onReceiveError、shouldOverrideUrlLoading 等;
- WebChromeClient 处理 JS 页面的事件响应,比如网页中的对话框、网页图标、网站标题、网页的加载进度等事件,对应的响应方法有 onJsAlert、onJsConfirm、onJsConsole、onProgressChanged、onReceiveIcon、onReceiveTitle 等。
# JSBridge 如何引用
- 由 Native 端进行注入:注入方式和 Native 调用 JavaScript 类似,直接执行桥的全部代码。
- 优点:桥的版本很容易与 Native 保持一致,Native 端不用对不同版本的 JSBridge 进行兼容。
- 缺点:注入时机不确定,需要实现注入失败后重试的机制,保证注入的成功率,同时 JavaScript 端在调用接口时,需要优先判断 JSBridge 是否已经注入成功。
- 由 JavaScript 端引用:直接与 JavaScript 一起执行。
- 优点:JavaScript 端可以确定 JSBridge 的存在,直接调用即可。
- 缺点:如果桥的实现方式有更改,JSBridge 需要兼容多版本的 Native Bridge 或者 Native Bridge 兼容多版本的 JSBridge。
- Q:如果在还没有注入 jsbridge API 之前调用了其中的方法怎么处理?
- A:参考微信 wxjsbrige,
document.addeventlistener("wxjsbrigeReady", todo); - 向目标派发(自定义)事件:
window.dispatchEvent(new Event('customEvent'));同步调用事件处理程序。 - 接收派发的事件:
window.addEventListener('customEvent',(e)=>{console.log('e',e.type);},false); - 另一种创建自定义事件的方法:
var evt = document.createEvent("HTMLEvents");evt.initEvent("alert", false, false);dom.dispatchEvent(evt); - 自定义事件的删除:
removeEventListener、detachEvent
- 另一种使用方式:JsBridge 框架的使用主要分为:
- 在 H5 页面加载完毕注入一个本地的 js 文件;
- Java 代码中注册 BridgeHandler,用来处理 JS 发送过来的消息;
- 在本地注入的 js 文件中定义_handleMessageFromNative,用来接收 java 传递过来的消息;
- 因为客户端注入 js 是异步的,所以需要在 js 文件中注册 Event 监听器,成功后通知 H5。
# 存在的问题
JSBridge 的改进建议,由于 webview 调用 js 方法的时候必须在主线程才能生效,所以偶然会出现 java 调用 js 失败。另外,Js 调用 Java 偶尔也会失败,因为 iframe 机制不能保证每次都能触发 shouldOverrideUrlLoading 回调。
# 页面加载时触发的事件及顺序
# 3 个事件
readystatechange 和 DOMContentLoaded 是通过 document 监听的;load 事件是 window 的事件。
# document.onreadystatechange 事件
对应的document.readyState属性描述了文档的加载状态,在整个加载过程中document.readyState会不断变化,每次变化都会触发readystatechange事件。readyState 的值变化:
- loading(正在加载):document 仍在加载。
- interactive(可交互):文档已被解析,"正在加载"状态结束,DOM 元素可以被访问,可以操作 DOM,对应 DOMContentLoaded 事件,但是诸如图像,样式表和框架之类的子资源仍在加载。
- complete(完成):文档和所有子资源已完成加载。表示 load 状态的事件即将被触发。对应 load 事件。
# document.DOMContentLoaded 事件
# window.onload 事件
此时页面加载完毕,正常展示,可以操作。
# window.onbeforeunload 事件
当窗口即将被卸载(关闭)时,会触发该事件。此时页面文档依然可见,且该事件的默认动作可以被取消。尽量避免使用window.onunload事件。区别在于 onbeforeunload 在 onunload 之前执行,它还可以阻止 onunload 的执行。
window.addEventListener("beforeunload", (event) => {
// Cancel the event as stated by the standard.
event.preventDefault();
// Chrome requires returnValue to be set.
event.returnValue = "";
});
2
3
4
5
6
# 代码示例
document.onreadystatechange = function () {
console.log(document.readyState);
};
document.addEventListener("DOMContentLoaded", (event) => {
console.log("DOMContentLoaded"); // 译者注:"DOM完全加载以及解析"
});
window.addEventListener("load", (event) => {
console.log("load");
});
// 打印结果如下:
// loading 打印不出来
// interactivate
// DOMContentLoaded
// complete
// load
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# 如何微调和修改前端依赖包
目前实践了 2 种方式作为依赖微调如下:
- 直接把依赖下载下来,然后修改相关的文件,然后重新打包。或者把这个依赖变成代码里的工具函数或者某个本地模块,然后修改相关的代码。
- 通过脚本在
npm的postinstall阶段去替换现有的文件,或者替换字符串; - 通过
patch-package直接在 node_modules 修改文件,然后patch-package生成 patch 文件,在postinstall阶段再 patch 回去; - 通过 webpack 打包工具中的
alias把原本依赖替换成新的依赖包;
# HTML 中新的标签和属性
- 原生懒加载:
<img src="xxx" loading="lazy">,<iframe src="content.html" loading="lazy"></iframe> - 隐藏的折叠组件:
<details>&<summary>,details[open]summary {color: #f00;} - 原生的对话框:
<dialog> - Meta 标签的隐藏功能:
<!-- 主题颜色控制 -->
<meta name="theme-color" content="#2196f3" />
<!-- iOS全屏模式 -->
<meta name="apple-mobile-web-app-capable" content="yes" />
<!-- 缓存控制 -->
<meta http-equiv="Cache-Control" content="no-cache, no-store, must-revalidate" />
<meta http-equiv="Pragma" content="no-cache" />
<meta http-equiv="Expires" content="0" />
2
3
4
5
6
7
8
9
10
- 输入类型:
<input type="color" value="#ff0000">,<input type="date" min="2023-01-01" max="2024-12-31">,还有 range 等 - 自定义数据:
<div data-user-info='{"id":123, "name":"John"}'></div>,CSS 联动:[data-status="error"] { border-color: red;} - 图片的进阶处理:
<!-- srcset与sizes优化 -->
<img
src="small.jpg"
srcset="medium.jpg 1000w, large.jpg 2000w"
sizes="(max-width: 600px) 100vw, 50vw"
alt="响应式图片" />
<!-- decoding异步解码 -->
<img src="huge-image.jpg" decoding="async" alt="大图" />
2
3
4
5
6
7
8
9
- 模板引擎:
<template>标签,优势:不立即渲染,可重复利用,保持 DOM 结构完整性。
<template id="cardTemplate">
<div class="card">
<h3 class="title"></h3>
<p class="content"></p>
</div>
</template>
<script>
const template = document.getElementById("cardTemplate");
const clone = template.content.cloneNode(true);
clone.querySelector(".title").textContent = "新卡片";
document.body.appendChild(clone);
</script>
2
3
4
5
6
7
8
9
10
11
12
13
- 可访问性隐藏技巧,而不是使用
display:none;或者visibility: hidden;
/* 视觉隐藏但可被屏幕阅读器识别 */
.sr-only {
position: absolute;
width: 1px;
height: 1px;
padding: 0;
margin: -1px;
overflow: hidden;
clip: rect(0, 0, 0, 0);
white-space: nowrap;
border: 0;
}
2
3
4
5
6
7
8
9
10
11
12
- 进阶操作
<!-- 1. 内容安全策略(CSP) -->
<meta http-equiv="Content-Security-Policy" content="default-src 'self'; script-src 'unsafe-inline'" />
<!-- 2. 预加载关键资源 -->
<link rel="preload" href="font.woff2" as="font" type="font/woff2" crossorigin />
<!-- 3. 性能优化属性 -->
<script defer src="app.js"></script>
<link rel="modulepreload" href="module.js" />
<!-- 4. 地理定位集成 -->
<button onclick="navigator.geolocation.getCurrentPosition(showPosition)">获取位置</button>
<!-- 5. 原生进度条 -->
<progress value="75" max="100"></progress>
2
3
4
5
6
7
8
9
10
11
# Web Worker 计算耗时任务
- 可以单个 worker 也可以多个 worker 并行计算。
<template>
<div>
<button @click="makeWorker">开始线程</button>
<!--在计算时 往input输入值时 没有发生卡顿-->
<p><input type="text" /></p>
</div>
</template>
<script>
import Worker from "worker-loader!./worker";
export default {
methods: {
makeWorker() {
// 获取计算开始的时间
let start = performance.now(); // 新建一个线程
let worker = new Worker(); // 线程之间通过postMessage进行通信
worker.postMessage(0); // 监听message事件
worker.addEventListener("message", (e) => {
// 关闭线程
worker.terminate(); // 获取计算结束的时间
let end = performance.now(); // 得到总的计算时间
let durationTime = end - start;
console.log("计算结果:", e.data);
console.log(`代码执行了 ${durationTime} 毫秒`);
});
},
},
};
</script>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
- web worker 除了单纯进行计算外,还可以结合离屏 canvas 进行绘图,提升绘图的渲染性能和使用体验:对于复杂的 canvas 绘图,可以避免阻塞主线程
Web Worker 的限制
- 在 Worker 线程的运行环境中没有 window 全局对象,也无法访问 DOM 对象
- Worker 中只能获取到部分浏览器提供的 API,如定时器、navigator、location、XMLHttpRequest 等
- 由于可以获取 XMLHttpRequest 对象,可以在 Worker 线程中执行 ajax 请求
- 每个线程运行在完全独立的环境中,需要通过 postMessage、 message 事件机制来实现的线程之间的通信
通信时长
- Worker 线程与主线程通信时长不超过 50ms,否则会卡顿
- 最终标准:
计算的运算时长 - 通信时长 > 50ms,推荐使用 Web Worker
原则上,运算时间超过 50ms 会造成页面卡顿,属于 Long task,这种情况就可以考虑使用 Web Worker。但还要先考虑通信时长的问题,新建一个 web worker 时, 浏览器会加载对应的worker.js资源,假如一个运算执行时长为 100ms,但是通信时长为 300ms,用了 Web Worker 可能会更慢。
Web Worker 的通信机制是异步的,所以 Web Worker 的通信时长不会影响 Web Worker 的执行时长。
好处优势
Web Worker 为前端带来了后端的计算能力,扩大了前端的业务边界可以实现主线程与复杂计运算线程的分离,从而减轻了因大量计算而造成 UI 阻塞的情况并且更大程度地利用了终端硬件的性能