# 图灵完备性
在可计算性理论,如果一系列操作数据的规则(如指令集、编程语言、细胞自动机)可以用来模拟任何图灵机,那么它是图灵完备的。这意味着这个系统也可以识别其他数据处理规则集,图灵完备性被用作表达这种数据处理规则集的一种属性。如今,几乎所有编程语言都是具有图灵完备性的。
# 好用的开发工具、插件
- Chrome 扩展:Access-Control-Allow-Origin 自动跨域插件,可以自行配置跨域域名方法等;
- Log 工具:VConsole,用于在移动端、H5 进行日志打印,方便调试;
# Mixed Content
混合内容是指 https 页面下有非 https 资源时,浏览器的加载策略。
在 Chrome 80 中,如果你的页面开启了 https,同时你在页面中请求了 http 的音频和视频资源,这些资源将将自动升级为 https ,并且默认情况下,如果它们无法通过 https 加载,Chrome 将阻止它们。这样就会造成一些未支持 https 协议的资源加载失败。
最合理的方案:
- 全站统一 https-但是有些时候内容是用户产生的,或者第三方数据;
- 同域-nginx 强制跳转 https NGINX 配置:server{listen xx.xx.xx.xx; server_name xx.com; rewrite ^(.*)$ https://$host$1 permanent;};
- 跨域的方案:
- 资源有 http 和 https 协议,但是 url 是 http 的, 兼容低版本浏览器;
<meta http-equiv="Content-Security-Policy" content="upgrade-insecure-requests"> - JS 拦截簒改 base host, 然后 Nginx 转发/后端代理;
# MIME sniffing 嗅探
引入 MIME sniffing 功能的初衷是用来弥补 Web 服务器响应一个图像请求时有可能返回错误的内容类型 Content-Type 信息这一缺陷;
嗅探攻击解决方案:
- 给返回内容加上对应的 contentType;
- 添加响应头
X-Content-Type-Options: nosniff,让浏览器不要尝试去嗅探;
- 嗅探乱码原因:
<meta charset="utf-8" >只对 HTML 内容解析有效,对于 css 内容中(外部样式表下)的双字节字符(如中文)解析并没有作用,如果浏览器请求回来的 css 资源的 HTTP 响应头里的Content-Type未指明"charset=utf-8"的话,浏览器根据自身的嗅探机制来决定采用哪一种编码解析,结果就会概率出现双字节字符乱码的情况; - 解决方法:
- css 资源请求的响应头的
Content-Type增加"charset=utf-8"声明; - 使用
@charset - 使用
css-unicode-loader
# Cookie/Set-Cookie
登录的原理:
问题:通过 http 方式访问一个 https 网站时,登录有时会失效(无法登陆、跳转),Cookies 中的 token 没有写成功
原因:http 和 https 返回的 tokenName 相同,由于一个是 insecure 一个是 secure 的,两者不能互相覆盖,导致 cookie 中的 sso-token 写入失败,所以也就无法登陆了。
查看接口,发现:Response Headers 中的 Set-Cookie 是拿到了返回值的,但是后面有个黄色三角感叹号,提示:This Set-Cookie was blocked because it was not sent over a secure connection and would have overwritten a cookie with the Secure attribute.
解决方案
- 使用 https,Set-Cookie 中会有 Secure 字段;
- 在 chrome 中打开链接:
chrome://flags/#site-isolation-trial-opt-out,搜索 samesite 上述三个选项禁用(设为 disable)后重启 chrome,问题解决; - 删掉 https 下的 token
- 无痕模式(有时也不行,是因为无痕模式打开时也写入了 cookie)
- 几种常见的策略
- Same Origin Policy
- Content Security Policy (CSP)
- Referrer-Policy
# 针对新版本 Chrome>90.x? Samesite 策略不能设置,导致开发时页面跳转出现问题
open -n /Applications/Google\ Chrome.app/ --args --disable-features=SameSiteByDefaultCookies
或
open -a "Google Chrome" --args --disable-features=SameSiteByDefaultCookies
2
3
4
5
完全关闭 Chrome,打开命令行运行上述命令。
# 删除文件/文件夹
- rimraf 包的作用:以包的形式包装 rm -rf 命令,用来删除文件和文件夹的,不管文件夹是否为空,都可删除
const rimraf = require("rimraf");
rimraf("./test.txt", function (err) {
// 删除当前目录下的 test.txt
console.log(err);
});
2
3
4
5
# 闭包
- 作用域链:在 JavaScript 里面,函数、块、模块都可以形成作用域(一个存放变量的独立空间),他们之间可以相互嵌套,作用域之间会形成引用关系,这条链叫做作用域链。
- 闭包是指函数能够记住并访问他的词法作用域,即使这个函数在词法作用域之外执行。
- 主要用途:数据隐藏,通过闭包创建私有变量,外部无法直接访问;实现模块和封装,闭包可以模拟 ES6 中的模块,实现代码封装。
- 在内存中,闭包通过作用域链保存对外部函数的引用,从而可以访问外部函数的变量,也导致外部函数的变量对象无法被回收,直到闭包被销毁。会导致内存占用增加,若使用不当会导致内存泄露。
- 如何清除闭包:将闭包赋值为 null,解除对外部函数的引用,使其变量对象可以被回收。
- 查看作用域链:
const parser = require("@babel/parser");
const traverse = require("@babel/traverse").default;
const code = `
function func() {
const guang = 'guang';
function func2() {
const ssh = 'ssh';
{
function func3 () {
const suzhe = 'suzhe';
}
}
}
}
`;
const ast = parser.parse(code);
traverse(ast, {
FunctionDeclaration(path) {
if (path.get("id.name").node === "func3") {
console.log(path.scope.dump());
}
},
});
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
函数和块的作用域内的变量声明会在作用域 (scope) 内创建一个绑定(变量名绑定到具体的值,也就是 binding),然后其余地方可以引用 (refer) 这个 binding,这样就是静态作用域链的变量访问顺序。
静态:因为这样的嵌套关系是分析代码就可以得出的,不需要运行,按照这种顺序访问变量的链就是静态作用域链,这种链的好处是可以直观的知道变量之间的引用关系。静态作用域链是可以做静态分析的。
JavaScript 除了静态作用域链外,还有一个特点就是函数可以作为返回值!这就会引出闭包。
父函数作用域中有很多东西与子函数无关,所以不会因为子函数没结束就一直常驻内存。这样肯定有性能问题,所以还是要销毁。但是销毁了父作用域不能影响子函数,所以要再创建个对象,要把子函数内引用(refer)的父作用域的变量打包里来,给子函数打包带走。
闭包的机制:销毁父作用域后,把用到的变量包起来,打包给子函数,放到一个属性上
[[Scopes]]。即使子函数没有引用父函数的变量,他也会有一个闭包--闭包最少会包含全局作用域。
需要打包的只是环境内没有的,也就是闭包只保存外部引用。然后是在创建函数的时候保存到函数属性上的,创建的函数返回的时候会打包给函数,但是 JS 引擎怎么知道它要用到哪些外部引用呢,需要做 AST 扫描,很多 JS 引擎会做 Lazy Parsing,这时候去 parse 函数,正好也能知道它用到了哪些外部引用,然后把这些外部用打包成 Closure 闭包,加到
[[scopes]]中。所以,闭包是返回函数的时候扫描函数内的标识符引用,把用到的本作用域的变量打成 Closure 包,放到
[[Scopes]]里。调用该函数的时候,JS 引擎 会取出[[Scopes]]中的打包的 Closure + Global 链,设置成新的作用域链, 这就是函数用到的所有外部环境了,有了外部环境,自然就可以运行了。闭包需要扫描函数内的标识符,做静态分析,那 eval 怎么办,他有可能内容是从网络记载的,从磁盘读取的等等,内容是动态的。
eval 确实没法分析外部引用,也就没法打包闭包,这种就特殊处理一下,打包整个作用域就好了。因为没法静态分析动态内容所以全部打包成闭包了,本来闭包就是为了不保存全部的作用域链的内容,结果 eval 导致全部保存了,所以尽量不要用 eval,会导致闭包保存内容过多。
但是 JS 引擎只处理了直接调用,也就是说直接调用 eval 才会打包整个作用域,如果不直接调用 eval,就没法分析引用,也就没法形成闭包了。
黑魔法,比如 利用「不直接调用 eval 不会生成闭包,会在全局上下文执行」的特性。
定义:闭包是在函数创建的时候,让函数打包带走的根据函数内的外部引用来过滤作用域链剩下的链。它是在函数创建的时候生成的作用域链的子集,是打包的外部环境。evel 因为没法分析内容,所以直接调用会把整个作用域打包(所以尽量不要用 eval,容易在闭包保存过多的无用变量),而不直接调用则没有闭包。
过滤规则:
- 全局作用域不会被过滤掉,一定包含。所以在何处调用函数都能访问到。
- 其余作用域会根据是否内部有变量被当前函数所引用而过滤掉一些。不是每个返回的子函数都会生成闭包。
- 被引用的作用域也会过滤掉没有被引用的 binding (变量声明)。只把用到的变量打个包。
# 闭包的缺陷
- JavaScript 引擎会把内存分为函数调用栈、全局作用域和堆,其中堆用于放一些动态的对象,调用栈每一个栈帧放一个函数的执行上下文,里面有一个 local 变量环境用于放内部声明的一些变量,如果是对象,会在堆上分配空间,然后把引用保存在栈帧的 local 环境中。全局作用域也是一样,只不过一般用于放静态的一些东西,有时候也叫静态域。
- 每个栈帧的执行上下文包含函数执行需要访问的所有环境,包括 local 环境、作用域链、this 等。
- 如果子函数返回了,也就是父函数执行完了,此时,首先父函数的栈帧会销毁,子函数这个时候其实还没有被调用,所以还是一个堆中的对象,没有对应的栈帧,这时候父函数把作用域链过滤出需要用到的,形成闭包链,设置到子函数的
[[Scopes]]属性上。 - 父函数销毁,栈帧对应的内存马上释放,用到的堆中的对象引用会被 gc 回收,而返回的函数会把作用域链过滤出用到的引用形成闭包链放在堆中。
- 这就导致了一个隐患:本来作用域是随着函数调用的结束而销毁的,因为整个栈帧都会被马上销毁。而形成闭包以后,转移到了堆内存。
- 当运行这个子函数的时候,子函数会创建栈帧,如果这个函数一直在运行,那么它在堆内存中的闭包就一直占用着内存,就会使可用内存减少,严重到一定程度就算是「内存泄漏」了。
- 所以闭包不要乱用,少打包一点东西到堆内存。
# 闭包为什么不会被销毁
如今的浏览器 GC 算法采用的都是标记清除,标记清除的依据是看对象的可达性,而闭包对 GC 来讲,本质上是内部函数的词法环境保持了对外部作用域变量的引用,因此这个对象是具备可达性这个条件的,被打上了 1 的二进制,因此不会被销毁。若是早期的浏览器采用的引用计数,引用计数清理垃圾的依据是看该对象的引用计数是否为 0 ,而闭包引用了外部作用域,那些对象的引用计数会 ++,不会回归到 0 ,因此不会销毁。
# JavaScript 中的事件循环 Event Loop
- 事件循环既可能是浏览器的主事件循环也可能是被一个 web worker 所驱动的事件循环。
- 原因:JavaScript 是单线程的语言!同一个时间只能做一件事情。
- 事件循环的具体流程如下:
- 从宏任务队列中,按照入队顺序,找到第一个执行的宏任务,放入调用栈,开始执行;
- 执行完该宏任务下所有同步任务后,即调用栈清空后,该宏任务被推出宏任务队列,然后微任务队列开始按照入队顺序,依次执行其中的微任务,直至微任务队列清空为止;
- 当微任务队列清空后,一个事件循环结束;
- 接着从宏任务队列中,找到下一个执行的宏任务,开始第二个事件循环,直至宏任务队列清空为止。
- 这里有几个重点:
- 当我们第一次执行的时候,解释器会将整体代码 script 放入宏任务队列中,因此事件循环是从第一个宏任务开始的;
- 如果在执行微任务的过程中,产生新的微任务添加到微任务队列中,也需要一起清空;微任务队列没清空之前,是不会执行下一个宏任务的。
# 调用栈 Call Stack
- 调用栈是解释器(比如浏览器中的 JavaScript 解释器)追踪函数执行流的一种机制。当执行环境中调用了多个函数时,通过这种机制,我们能够追踪到哪个函数正在执行,执行的函数体中又调用了哪个函数。具有 LIFO(后进先出,Last in First Out)的结构。调用栈内存放的是代码执行期间的所有执行上下文。
- 每调用一个函数,解释器就会把该函数添加进调用栈并开始执行。
- 正在调用栈中执行的函数还调用了其它函数,那么新函数也将会被添加进调用栈,一旦这个函数被调用,便会立即执行。
- 当前函数执行完毕后,解释器将其清出调用栈,继续执行当前执行环境下的剩余的代码。
- 当分配的调用栈空间被占满时,会引发“堆栈溢出”错误。
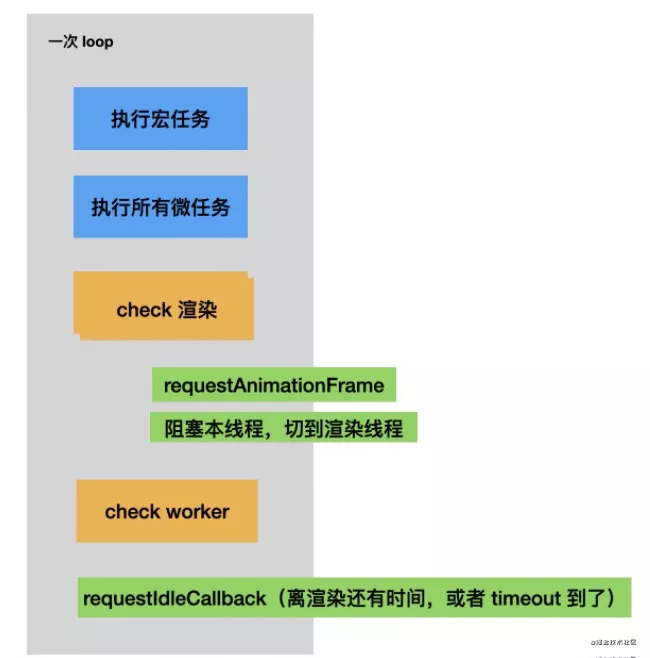
- 浏览器里有 JS 引擎做 JS 代码的执行,利用注入的浏览器 API 完成功能,有渲染引擎做页面渲染,两者都比较纯粹,需要一个调度的方式,就是 event loop。
- event loop 实现了 task 和 急事处理机制 microtask,而且每次 loop 结束会 check 是否要渲染,渲染之前会有 requestAnimationFrames 生命周期。
- 帧刷新不能被拖延否则会卡顿甚至掉帧,所以就需要 JS 代码里面不要做过多计算,于是有了 requestIdleCallback 的 api,希望在每次 check 完发现还有时间就执行,没时间就不执行(这个 deadline 的时间也作为参数让 js 代码自己判断),为了避免一直没时间,还提供了 timeout 参数强制执行。
- 防止计算时间过长导致渲染掉帧是 ui 框架一直关注的问题,就是怎么不阻塞渲染,让逻辑能够拆成帧间隔时间内能够执行完的小块。浏览器提供了 idelcallback 的 api,很多 ui 框架也通过递归改循环然后记录状态等方式实现了计算量的拆分,目的只有一个:loop 内的逻辑执行不能阻塞 check,也就是不能阻塞渲染引擎做帧刷新。所以不管是 JS 代码宏微任务、 requestAnimationCallback、requestIdleCallback 都不能计算时间太长。这个问题是前端开发的持续性阵痛。
- js 引擎包括 parser、解释器、gc 再加一个 JIT 编译器这几部分。
- parser:负责把 javascript 源码转成 AST
- interpreter:解释器, 负责转换 AST 成字节码,并解释执行
- JIT compiler:对执行时的热点函数进行编译,把字节码转成机器码,之后可以直接执行机器码
- gc(garbage collector):垃圾回收器,清理堆内存中不再使用的对象
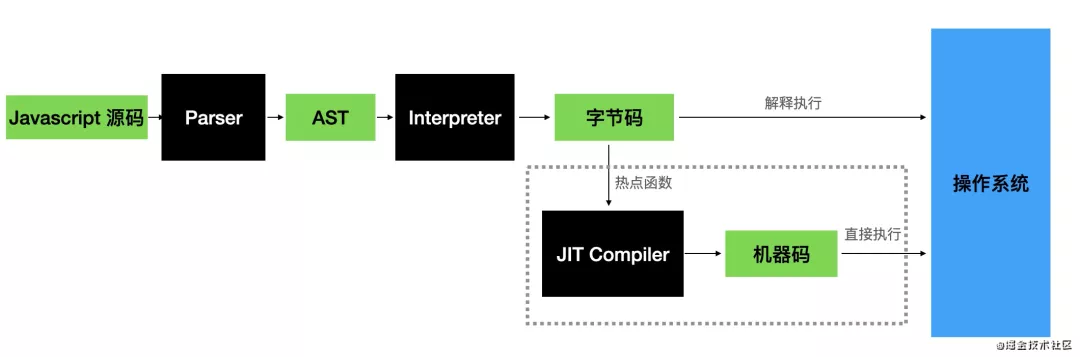
- 如图,一般的 JS 引擎的编译流水线是 parse 源码成 AST,之后 AST 转为字节码,解释执行字节码。运行时会收集函数执行的频率,对于到达了一定阈值的热点代码,会把对应的字节码转成机器码(JIT),然后直接执行。这就是 js 代码能够生效的流程。
# 任务与微任务
有两点关键的区别:
- 首先,每当一个任务存在,事件循环都会检查该任务是否正把控制权交给其他 JavaScript 代码。如若不然,事件循环就会运行微任务队列中的所有微任务。接下来微任务循环会在事件循环的每次迭代中被处理多次,包括处理完事件和其他回调之后。
- 其次,如果一个微任务通过调用 queueMicrotask(), 向队列中加入了更多的微任务,则那些新加入的微任务 会早于下一个任务运行 。这是因为事件循环会持续调用微任务直至队列中没有留存的,即使是在有更多微任务持续被加入的情况下。
任务进入任务队列,其实会利用到浏览器的其他线程。虽然说 JavaScript 是单线程语言,但是浏览器不是单线程的。而不同的线程就会对不同的事件进行处理,当对应事件可以执行的时候,对应线程就会将其放入任务队列。
浏览器线程:
- js 引擎线程:用于解释执行 js 代码、用户输入、网络请求等;
- GUI 渲染线程:绘制用户界面,与 JS 主线程互斥(因为 js 可以操作 DOM,进而会影响到 GUI 的渲染结果);
- http 异步网络请求线程:处理用户的 get、post 等请求,等返回结果后将回调函数推入到任务队列;
- 定时触发器线程:setInterval、setTimeout 等待时间结束后,会把执行函数推入任务队列中;
- 浏览器事件处理线程:将 click、mouse 等 UI 交互事件发生后,将要执行的回调函数放入到事件队列中。
简单总结宏任务与微任务的执行顺序:
- 在执行上下文栈的同步任务执行完后;
- 首先执行 Microtask 队列,按照队列先进先出的原则,一次执行完所有 Microtask 队列任务;
- 然后执行 Macrotask/Task 队列,一次执行一个,一个执行完后,检测 Microtask 是否为空;
- 为空则执行下一个 Macrotask/Task;
- 不为空则执行 Microtask
# Canvas 绘图的一些坑
- Canvas 绘制高度受浏览器的限制,不能无限绘制,可以通过设置宽高比例进行一定的调整,降低绘制图片的质量。
- 相关文章 1 (opens new window)
- 相关文章 2 (opens new window)
# 预览 PDF 文件
# iframe
url 后面拼接
#page=1&view=FitH,top&toolbar=0可以把打印下载等功能隐藏设置 response 的 Header 使得 Chrome 浏览器打开 PDF 而不自动下载
// 其中比较关键的是Content-Disposition是inline而不是attachment,这样提示浏览器来显示文档而不是下载
response.setContentType("application/pdf");
response.setHeader("Content-Disposition", "inline;fileName=XXXX.pdf");
2
3
PS: response-content-disposition=attachment;fileName=XXXX.pdf时,会直接下载文件而不会预览。
PS: 对于 AWS ECS 中的文件预览,需要做相应配置!参考 (opens new window)
- 由上 2 已知带有
content-disposition=attachment头部的 pdf 文件在 Chrome 下是无法预览的,一种巧妙的思路是,先用 fetch 下载下来拿到 blob 对象,然后再用URL.createObjectURL生成临时 URL,然后就可以预览啦,代码如下:
// 实际测试貌似依然不可,尤其是针对文件服务器还需要鉴权时
fetch("xxx.pdf")
.then((resp) => resp.blob())
.then((blob) => {
var url = URL.createObjectURL(blob);
document.querySelector("object").data = url;
});
2
3
4
5
6
7
- 注意事项:当 url 是同源(同域名、同协议、同端口号)时,这时如果给 a 标签加上了 download 属性,那么 download 属性会指示浏览器该下载而不是打开该文件,同时该属性值即下载时的文件名,哪怕此时的 href 只是个普通链接,也会下载这个 HTML 页面;
# react-pdf
- 基于 pdf.js
- 参考一个实例 (opens new window)
const useWindowWidth = () => {
const [width, setWidth] = useState(window.innerWidth);
useEffect(() => {
const handleResize = () => setWidth(window.innerWidth);
window.addEventListener("resize", handleResize);
return () => {
window.removeEventListener("resize", handleResize);
};
}, []);
return width;
};
const MyApp = () => {
const width = useWindowWidth();
const [numPages, setNumPages] = useState(null);
const onDocumentLoadSuccess = ({ numPages: page }) => {
Toast.hide();
setNumPages(page);
};
const onDocumentLoadError = (error) => {
Toast.fail("加载失败,请重试", 3);
};
const onLoading = () => {
Toast.loading("努力加载中...");
};
return (
<PageWrapper>
<Header title="详情" />
<PDFWrapper>
<Document
style={{ width: "100%" }}
file={history.location?.state?.pdfurl}
onLoadSuccess={onDocumentLoadSuccess}
onLoadError={onDocumentLoadError}
loading={onLoading}>
{Array.from(new Array(numPages), (el, index) => (
<Page key={`page_${index + 1}`} pageNumber={index + 1} width={width} />
))}
</Document>
</PDFWrapper>
</PageWrapper>
);
};
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
# pdfh5
- 基于 pdf.js
# PDFObject
- 基于 pdf.js
# pdf.js
- 参考 GitHub
- 关闭 pdf 缓存:不使用 pdf.workers.js,设置
PDFViewerApplication.viewerPrefs.showPreviousViewOnLoad = false
# react-pdf-viewer
- 基于 pdf.js
import React from 'react';
import { Viewer, Worker, LocalizationMap, SpecialZoomLevel } from '@react-pdf-viewer/core';
import { defaultLayoutPlugin } from '@react-pdf-viewer/default-layout';
import queryString from 'query-string';
import '@react-pdf-viewer/core/lib/styles/index.css';
import '@react-pdf-viewer/default-layout/lib/styles/index.css';
// import zh_CN from '@react-pdf-viewer/locales/lib/zh_CN.json';
import zh_CN from './zh_CN.json';// 自定义json 参考/demos/previewPDF/zh_CN.json
const App = () => {
const defaultLayoutPluginInstance = defaultLayoutPlugin();
const { file } = queryString.parse(window.location.search);
return (
<Worker workerUrl={window._config.worker_api as string}>
<div
style={{
width: '100%',
marginLeft: 'auto',
marginRight: 'auto',
}}
>
<Viewer
theme="dark"
defaultScale={SpecialZoomLevel.ActualSize}
fileUrl={file}
plugins={[defaultLayoutPluginInstance]}
localization={zh_CN as any as LocalizationMap}
/>
</div>
</Worker>
);
};
export default App;
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
# Taro 接入友盟
# JSON.stringify()
JSON.stringify(value[, replacer [, space]]) 方法将一个 JavaScript 对象或值转换为 JSON 字符串,如果指定了一个 replacer 函数,则可以选择性地替换值,或者指定的 replacer 是数组,则可选择性地仅包含数组指定的属性。
- value
- 将要序列化成 一个 JSON 字符串的值。
- replacer 可选
- 如果该参数是一个函数(接收 key 和 value),则在序列化过程中,被序列化的值的每个属性都会经过该函数的转换和处理;
- 如果该参数是一个数组,则只有包含在这个数组中的属性名才会被序列化到最终的 JSON 字符串中;
- 如果该参数为 null 或者未提供,则对象所有的属性都会被序列化。
- space 可选
- 指定缩进用的空白字符串,用于美化输出(pretty-print);
- 如果参数是个数字,它代表有多少的空格;上限为 10。
- 该值若小于 1,则意味着没有空格;
- 如果该参数为字符串(当字符串长度超过 10 个字母,取其前 10 个字母),该字符串将被作为空格;
- 如果该参数没有提供(或者为 null),将没有空格。
# Feature1
- undefined、任意的函数以及 symbol 值,出现在非数组对象的属性值中时在序列化过程中会被忽略
- undefined、任意的函数以及 symbol 值出现在数组中时会被转换成 null
- undefined、任意的函数以及 symbol 值被单独转换时,会返回 undefined
# Feature2
- 布尔值、数字、字符串的包装对象在序列化过程中会自动转换成对应的原始值。
# Feature3
- 所有以 symbol 为属性键的属性都会被完全忽略掉,即便 replacer 参数中强制指定包含了它们。
# Feature4
- NaN 和 Infinity 格式的数值及 null 都会被当做 null。
# Feature5
- 转换值如果有 toJSON() 方法,该方法定义什么值将被序列化。
# Feature6
- Date 日期调用了 toJSON() 将其转换为了 string 字符串(同 Date.toISOString()),因此会被当做字符串处理。
# Feature7
- 对包含循环引用的对象(对象之间相互引用,形成无限循环)执行此方法,会抛出错误。
# Feature8
- 其他类型的对象,包括 Map/Set/WeakMap/WeakSet,仅会序列化可枚举的属性
# Feature9
- 当尝试去转换 BigInt 类型的值会抛出错误
// 默认情况下数据是这样的
var signInfo = [
{
fieldId: 539,
value: undefined,
},
{
fieldId: 539,
value: "",
},
{
fieldId: 539,
value: null,
},
{
fieldId: 539,
value: "undefined",
},
{
fieldId: 539,
value: "null",
},
{
fieldId: 540,
value: Symbol("555"),
},
{
fieldId: 540,
value: Symbol.for("555"),
},
{
fieldId: 546,
value: function () {
console.log(1110);
},
},
];
// 经过JSON.stringify之后的数据,少了value key,导致后端无法读取value值进行报错
// 具体原因是`undefined`、`任意的函数`以及`symbol值`,出现在`非数组对象`的属性值中时在序列化过程中会被忽略
console.log(JSON.stringify(signInfo1));
// [{"fieldId":539},{"fieldId":539,"value":""},{"fieldId":539,"value":null},{"fieldId":539,"value":"undefined"},{"fieldId":539,"value":"null"},{"fieldId":540},{"fieldId":540},{"fieldId":546}]
// 对于数组
var arr = [
undefined,
"undefined",
null,
"null",
function () {
console.log(1110);
},
];
console.log(JSON.stringify(arr));
// [null,"undefined",null,"null",null]
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
# 文字转语音
//语音播报
function voiceAnnouncements(str) {
// 百度语音合成:或者使用新版地址https://tsn.baidu.com/text2audio
var url = "http://tts.baidu.com/text2audio?lan=zh&ie=UTF-8&spd=5&text=" + encodeURI(str);
var n = new Audio(url);
n.src = url;
n.play();
}
voiceAnnouncements(`
秋名山上路人稀,常有车手较高低;
如今车道依旧在,不见当年老司机。
司机车技今尚好,前端群里不寂寥;
向天再借五百年,誓言各行领风骚。
`);
// 尝试了一些换女声的方式,但是,都失败了。。。
voiceAnnouncements(`
哇,代码写的真棒,你可真秀哇!
`);
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# 使用 stringObject.localeCompare(target) 方法实现中文按照拼音顺序排序
# 把 target 以本地特定的顺序与 stringObject 进行比较,如果 stringObject 小于 target,则 localeCompare() 返回小于 0 的数。如果 stringObject 大于 target,则该方法返回大于 0 的数。如果两个字符串相等,或根据本地排序规则没有区别,该方法返回 0。
- 例:
'HangJinLu'.localeCompare('HanZhongLu'),返回 number: -1 - 把
<和>运算符应用到字符串时,它们只用字符的 Unicode 编码比较字符串,而不考虑当地的排序规则。以这种方法生成的顺序不一定是正确的!!! - 例:
'HangJinLu'>'HanZhongLu';//返回 true str.sort (function(a,b){return a.localeCompare(b)});// 用本地特定排序规则对字符串数组进行排序
# 前端下载文件的方式
- 目前前端直接下载 web 服务器或者 CDN 静态资源的方式有两种,一个是利用 a 标签,另一个是通过 window.open() 函数。
# 利用 a 标签
对本地图片,给 a 标签添加 download 属性后,用浏览器打开 html 文件后,点击超链接,弹出了路径选择窗口,点击保存,图片完成下载。
对网络图片,点击下载的超链接,会发现并没有开始下载,而是在新标签页打开了图片。PS:如果你的网络图片渲染不出来,尝试在标签内添加
<meta name="referrer" content="no-referrer">- 没有开始下载原因——很可能是浏览器的同源策略导致 download 属性失效造成的,失效之后做的仅仅是跳转功能。
- 由上可知,download 属性只适用于同源 URL。
- 可以使用 blob:URL 和 data:URL,以方便用户下载使用 js 生成的内容。
- 若 HTTP 头中的 Content-Disposition 属性赋予了一个不同于 download 属性的文件名,则 HTTP 头属性优先级更高。
- 若 HTTP 头中的 Content-Disposition 被设置为 inline,那么 Chrome, and Firefox 82 and later 会优先考虑 download 并把 Content-Disposition 视为 download,Firefox versions before 82 会优先考虑 Content-Disposition 且会展示 content inline。
换个推流的方式,也就是用 js 将资源按照二进制流的方式读取,对二进制流生成一个 url,这个 url 是我们自己站点可访问的 url ,没有禁止跨域的限制。把 url 绑定到
<a>标签的 href 属性中,因为浏览器无法打开二进制流文件,所以对于这样的资源,浏览器将开始下载而不是在新标签页打开资源。参考下面的 axios 文件下载。
# 通过 window.open()
window.open(url,'_self') || window.open(url,'_blank')
# axios 文件下载
import { message } from "antd";
import _ from "lodash";
import axios, { AxiosRequestConfig } from "axios";
interface axiosDownloadParams {
url: string;
params: any;
method: "GET" | "POST" | "get" | "post";
pFileName?: string;
baseURL: string;
failCallback?: (error: { code: number; message: string }) => void;
successCallback?: () => void;
}
/**
* get请求,判断正则表达式
*/
const getRegex = /^get$/i;
/**
* 非get请求,下载资源
* @param url 请求url
* @param params 请求参数
* @param method 请求方法
*/
const axiosDownload =
({ url, params, method, baseURL, pFileName, failCallback, successCallback }: axiosDownloadParams) =>
() => {
// ajax 参数类型
const axiosConfig: AxiosRequestConfig = {
method,
url,
baseURL,
responseType: "blob",
};
if (getRegex.test(method)) {
axiosConfig.params = params || {};
} else {
axiosConfig.data = params || {};
}
// 发起ajax请求
axios(axiosConfig).then((res) => {
// 获取响应数据
const { data, headers } = res || {};
if (data.type === "application/json") {
const reader = new FileReader();
reader.readAsText(data, "utf-8");
reader.onload = () => {
const error = JSON.parse(reader.result as string);
if (failCallback) {
failCallback(error);
} else {
message.error(error.message);
}
};
} else {
// 获取【文件信息头】
const disposition = _.get(headers, "content-disposition");
// 获取【文件名称】
const fileName = decodeURIComponent(_.last(_.split(disposition, "=")) || "") || pFileName || "file.xlsx";
// 获取【文件内容】
const content = data as BlobPart;
// 构建文件【二进制内容】
const blob = new Blob([content], {
type: "application/octet-stream",
});
// 如果是非IE下载
if ("download" in document.createElement("a")) {
// 非IE下载
const elink = document.createElement("a");
elink.download = fileName;
elink.style.display = "none";
elink.href = URL.createObjectURL(blob);
document.body.appendChild(elink);
elink.click();
URL.revokeObjectURL(elink.href); // 释放URL 对象
document.body.removeChild(elink);
// elink.remove();
} else {
// IE10+下载
navigator.msSaveBlob && navigator.msSaveBlob(blob, fileName);
}
successCallback?.();
}
});
};
export default axiosDownload;
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
# axios 提交表单
const uploadService = (file: FormData) =>
axios("/web/xxx", {
method: "POST",
data: file,
headers: { "Content-Type": "multipart/form-data" },
}).then((res) => res.data);
2
3
4
5
6
# #!/usr/bin node 和 #!/usr/bin/env node 两者的区别
是 Unix 和 Linux 脚本语言的第一行,目的就是指出,你想要你的这个文件中的代码用什么可执行程序去运行它
#!/usr/bin node是告诉操作系统执行这个脚本的时候,调用/usr/bin 下的 node 解释器;#!/usr/bin/env node这种用法是为了防止操作系统用户没有将 node 装在默认的/usr/bin 路径里。当系统看到这一行的时候,首先会到 env 设置里查找 node 的安装路径,再调用对应路径下的解释器程序完成操作。#!/usr/bin node相当于写死了 node 路径;#!/usr/bin/env node会去环境设置寻找 node 目录,推荐这种写法。
# 更新命令
npx browserslist@latest --update-db
# npm/yarn 代理设置
- NPM 设置代理:
npm config set proxy="<http_proxy>"
npm confit set https-proxy="<https_proxy>"
2
- NPM 删除代理:
npm config delete proxy
npm config delete https-proxy
2
- YARN 设置代理:
yarn config set proxy <http_proxy>
yarn config set https-proxy <https_proxy>
2
- YARN 删除代理:
yarn config delete proxy
yarn config delete https-proxy
2
- 另外,设置 registry 如下
npm config set registry https://registry.npm.taobao.org/
npm config set registry https://registry.npmjs.org/
yarn config set registry https://registry.npm.taobao.org/
yarn config set registry https://registry.npmjs.org/
2
3
4
5
# 为什么标签语义化
- 代码结构: 使页面没有 css 的情况下,也能够呈现出很好的内容结构。
- 有利于 SEO: 爬虫依赖标签来确定关键字的权重,因此可以和搜索引擎建立良好的沟通,帮助爬虫抓取更多的有效信息。
- 提升用户体验: 例如 title、alt 可以用于解释名称或者解释图片信息,以及 label 标签的灵活运用。
- 便于团队开发和维护: 语义化使得代码更具有可读性,让其他开发人员更加理解你的 html 结构,减少差异化。
- 方便其他设备解析: 如屏幕阅读器、盲人阅读器、移动设备等,以有意义的方式来渲染网页。
# node.process
- process 对象提供一系列属性,用于返回系统信息。
- process.argv:返回一个数组,成员是当前进程的所有命令行参数。
- process.env:返回一个对象,成员为当前 Shell 的环境变量,比如 process.env.HOME。
- process.installPrefix:返回一个字符串,表示 Node 安装路径的前缀,比如/usr/local。相应地,Node 的执行文件目录为/usr/local/bin/node。
- process.pid:返回一个数字,表示当前进程的进程号。
- process.platform:返回一个字符串,表示当前的操作系统,比如 Linux。
- process.title:返回一个字符串,默认值为 node,可以自定义该值。
- process.version:返回一个字符串,表示当前使用的 Node 版本,比如 v7.10.0。
- process 对象还有一些属性,用来指向 Shell 提供的接口。
- process.stdout 属性返回一个对象,表示「标准输出」。该对象的 write 方法等同于 console.log,可用在标准输出向用户显示内容。
- process.stdin 返回一个对象,表示「标准输入」。
- 由于 process.stdout 和 process.stdin 与其他进程的通信,都是流(stream)形式,所以必须通过 pipe 管道命令中介。
- 由于 stdin 和 stdout 都部署了 stream 接口,所以可以使用 stream 接口的方法。
- process.stderr 属性指向标准错误。
- process.argv 属性返回一个数组,由命令行执行脚本时的各个参数组成。它的第一个成员总是 node,第二个成员是脚本文件名,其余成员是脚本文件的参数。
- process.execPath 属性返回执行当前脚本的 Node 二进制文件的绝对路径。
- process.execArgv 属性返回一个数组,成员是命令行下执行脚本时,在 Node 可执行文件与脚本文件之间的命令行参数。
- process.env 属性返回一个对象,包含了当前 Shell 的所有环境变量。比如,process.env.HOME 返回用户的主目录。
- 通常的做法是,新建一个环境变量 NODE_ENV,用它确定当前所处的开发阶段,生产阶段设为 production,开发阶段设为 develop 或 staging,然后在脚本中读取 process.env.NODE_ENV 即可。
- process 对象提供以下方法:
- process.chdir():切换工作目录到指定目录。
- process.cwd():返回运行当前脚本的工作目录的路径。
- process.exit():退出当前进程。
- process.getgid():返回当前进程的组 ID(数值)。
- process.getuid():返回当前进程的用户 ID(数值)。
- process.nextTick():指定回调函数在当前执行栈的尾部、下一次 Event Loop 之前执行。
- process.on():监听事件。
- process.setgid():指定当前进程的组,可以使用数字 ID,也可以使用字符串 ID。
- process.setuid():指定当前进程的用户,可以使用数字 ID,也可以使用字符串 ID。
- 注意,process.cwd()与__dirname 的区别
- 前者是进程发起时的位置,后者是脚本的位置,两者可能是不一致的。
- 比如,node ./code/program.js,对于 process.cwd()来说,返回的是当前目录(.);
- 对于__dirname 来说,返回是脚本所在目录,即./code/program.js。
- process.nextTick()
- setTimeout(f,0)是将任务放到下一轮事件循环的头部,因此 nextTick 会比它先执行。另外,nextTick 的效率更高,因为不用检查是否到了指定时间。
- 根据 Node 的事件循环的实现,基本上,进入下一轮事件循环后的执行顺序如下:
- setTimeout(f,0)
- 各种到期的回调函数
- process.nextTick push(), sort(), reverse(), and splice()
- process.exit 方法用来退出当前进程。
- 它可以接受一个数值参数,如果参数大于 0,表示执行失败;如果等于 0 表示执行成功。如果不带有参数,exit 方法的参数默认为 0。
- 注意,process.exit()很多时候是不需要的。因为如果没有错误,一旦事件循环之中没有待完成的任务,Node 本来就会退出进程,不需要调用 process.exit(0)。这时如果调用了,进程会立刻退出,不管有没有异步任务还在执行,所以不如等 Node 自然退出。另一方面,如果发生错误,Node 往往也会退出进程,也不一定要调用 process.exit(1)。
- 更安全的方法是使用 exitcode 属性,指定退出状态,然后再抛出一个错误。
- process.exit()执行时,会触发 exit 事件。
- process 对象部署了 EventEmitter 接口,可以使用 on 方法监听各种事件,并指定回调函数。process 支持的事件还有下面这些:
- data 事件:数据输出输入时触发
- SIGINT 事件:接收到系统信号 SIGINT 时触发,主要是用户按 Ctrl + c 时触发。
- SIGTERM 事件:系统发出进程终止信号 SIGTERM 时触发
- exit 事件:进程退出前触发
- process.kill 方法用来对指定 ID 的线程发送信号,默认为 SIGINT 信号。
eg. process.kill(process.pid, 'SIGTERM'); # 杀死当前进程
- process 事件
- exit 事件:当前进程退出时,会触发 exit 事件,可以对该事件指定回调函数。
- beforeExit 事件:beforeExit 事件在 Node 清空了 Event Loop 以后,再没有任何待处理的任务时触发。正常情况下,如果没有任何待处理的任务,Node 进程会自动退出,设置 beforeExit 事件的监听函数以后,就可以提供一个机会,再部署一些任务,使得 Node 进程不退出。
- beforeExit 事件与 exit 事件的主要区别是,beforeExit 的监听函数可以部署异步任务,而 exit 不行。
- 此外,如果是显式终止程序(比如调用 process.exit()),或者因为发生未捕获的错误,而导致进程退出,这些场合不会触发 beforeExit 事件。因此,不能使用该事件替代 exit 事件。
- uncaughtException 事件:当前进程抛出一个没有被捕捉的错误时,会触发 uncaughtException 事件。
- 部署 uncaughtException 事件的监听函数,是免于 Node 进程终止的最后措施,否则 Node 就要执行 process.exit()。出于除错的目的,并不建议发生错误后,还保持进程运行。
- 抛出错误之前部署的异步操作,还是会继续执行。只有完成以后,Node 进程才会退出。
- 信号事件:操作系统内核向 Node 进程发出信号,会触发信号事件。实际开发中,主要对 SIGTERM 和 SIGINT 信号部署监听函数,这两个信号在非 Windows 平台会导致进程退出,但是只要部署了监听函数,Node 进程收到信号后就不会退出。
- 进程的退出码
进程退出时,会返回一个整数值,表示退出时的状态。这个整数值就叫做退出码。
- 0,正常退出
- 1,发生未捕获错误
- 5,V8 执行错误
- 8,不正确的参数
- 128 + 信号值,如果 Node 接受到退出信号(比如 SIGKILL 或 SIGHUP),它的退出码就是 128 加上信号值。由于 128 的二进制形式是 10000000, 所以退出码的后七位就是信号值。
- Bash 可以使用环境变量$?,获取上一步操作的退出码。
# 小程序调试
- debugx5.qq.com
- vconsole
# 八个笔试&面试仓库
- Front-end Developer Interview Questions 网址:https://h5bp.org/Front-end-Developer-Interview-Questions/
- CS-Interview-knowledge-Map 网址:https://github.com/InterviewMap/CS-Interview-Knowledge-Map
- Daily-Question 网址:https://github.com/shfshanyue/Daily-Question
- Daily-Interview-Question 网址:https://github.com/Advanced-Frontend/Daily-Interview-Question
- fe-interview 大前端面试宝典 网址:https://lucifer.ren/fe-interview
- 前端硬核面试专题 网址:https://github.com/biaochenxuying/blog/blob/master/interview/fe-interview.md
- LeetCode 算法试题学习 网址:https://leetcode-cn.com/problemset/all
- LeetCode 算法试题学习 网址:https://www.nowcoder.com/
# 需求:网站 A 中需要通过 iframe 加载网站 B 的页面
# 解决方法 1:代码中设置 Access-Control-Allow-Origin
PHP:
header("Access-Control-Allow-Origin: *"); //允许所有
header("Access-Control-Allow-Origin: https://test.com"); //允许指定域名
2
# 解决方法 2:web 服务器中配置
# 2.1:如果 web 服务器是 Apache
<Directory "/var/www/html">
AllowOverride None
Require all granted
Header set Access-Control-Allow-Origin *
</Directory>
2
3
4
5
# 2.2:如果 web 服务器是 Nginx
add_header Access-Control-Allow-Origin *;
add_header Access-Control-Allow-Methods GET,POST,OPTIONS;
add_header Access-Control-Allow-Headers 'DNT,X-Mx-ReqToken,Keep-Alive,User-Agent,X-Requested-With,If-Modified-Since,Cache-Control,Content-Type,access-control-allow-origin,Authorization';
2
3
# 解决方法 3:如果是 django 网站
- 安装 django-cors-headers
- 然后参考https://www.cnblogs.com/randomlee/p/9752705.html中的配置
# X-Frame-Options
X-Frame-Options 有三个可能的值:
X-Frame-Options: denyX-Frame-Options: sameoriginX-Frame-Options: allow-from https://example.com/换一句话说,如果设置为 deny,不光在别人的网站 frame 嵌入时会无法加载,在同域名页面中同样会无法加载。另一方面,如果设置为 sameorigin,那么页面就可以在同域名页面的 frame 中嵌套。- deny
- 表示该页面不允许在 frame 中展示,即便是在相同域名的页面中嵌套也不允许。
- sameorigin
- 表示该页面可以在相同域名页面的 frame 中展示。
- allow-from uri
- 表示该页面可以在指定来源的 frame 中展示。
# 使用 iframe 结合 postMessage 给 localStorage 扩容。
- 思路如下:
- 在【A 域】下引入【B 域】,【A 域】空间足够时,读写由【A 域】来完成,数据存在【A 域】下;
- 【A 域】空间不够需要在【B 域】读写时,通过 postMessage 向【B 域】发送跨域消息,【B 域】监听跨域消息,在接到指定的消息时进行读写操作;
- 【B 域】接到跨域消息时,如果是写入删除可以不做什么,如果是读取,就要先读取本域本地数据通过 postMessage 向父页面发送消息;
- 【A 域】在读取【B 域】数据时就需要监听来自【B 域】的跨域消息;
- 注意事项:
- window.postMessage()方法,向【B 域】发消息,应用
window.frames[0].postMessage()这样 iframe 内的【B 域】才可以接到; - 同理,【B 域】向 【A 域】发消息时应用,
window.parent.postMessage(); - 【A 域】的逻辑一定要在 iframe 加载完成后进行;
# 判断 iframe 加载完成
var iframe = document.createElement("iframe");
iframe.src = "https://ericyangxd.top";
if (iframe.attachEvent) {
iframe.attachEvent("onload", function () {
alert("Local iframe is now loaded.");
});
} else {
iframe.onload = function () {
alert("Local iframe is now loaded.");
};
}
document.body.appendChild(iframe);
2
3
4
5
6
7
8
9
10
11
12
# localStorage
- localStorage 存储的键值采用什么字符编码?—— UTF-16 DOMString,每个字符使用两个字节,是有前提条件的,就是码点小于 0xFFFF(65535), 大于这个码点的是四个字节。
- localStorage 存储 5M 的单位是什么?—— 5M 字符的长度值或 5M utf-16 编码单元,或者根据 UTF-16 编码规则,要么 2 个字节,要么 4 个字节,所以不如说是 10M 的「字节数/字节空间」,更为合理。字符的个数,并不等于字符的长度:"𠮷".length; // 2
- localStorage 键占不占存储空间?占!
- 使用以下方法「正确」获取长度:
Array.from("𠮷").length; // 1 - 获取一些组合字符的长度:例如:
'q̣̇' =unicode= 'q\u{0307}\u{0323}'
const getStringLength = function (string) {
const regex = /(\P{Mark})(\p{Mark}+)/gu;
const str = string.replace(regex, ($0, $1, $2) => $1);
return Array.from(str).length;
};
export default getStringLength;
2
3
4
5
6
- 字符串反转
const getReverseString = function (string) {
return Array.from(string).reverse().join("");
};
export default getReverseString;
2
3
4
- 根据码位获取字符串:
String.fromCodePoint(0x20bb7) // '𠮷' - 根据字符串获取码位:
'𠮷'.codePointAt().toString(16) // 20bb7 - 遍历字符串
for (let item of "𠮷") {
console.log(item); // '𠮷'
}
2
3
- 键的数量对读取性能有影响,但是不大。值的大小对性能影响更大,不建议保存大的数据。
- 写个方法统计一个 localStorage 已使用空间:
// 现代浏览器的精写版本:
function sizeOfLS() {
return Object.entries(localStorage)
.map((v) => v.join(""))
.join("").length;
}
2
3
4
5
6
- WHATWG 超文本应用程序技术工作组的 localstorage 协议定了 localStorage 的方法,属性等等,并没有明确规定其存储空间。也就导致各个浏览器的最大限制不一样。其并不是 ES 的标准。
- html 页面的 utf-8 编码
<meta charset="UTF-8">和 localStorage 的存储没有半毛钱的关系。
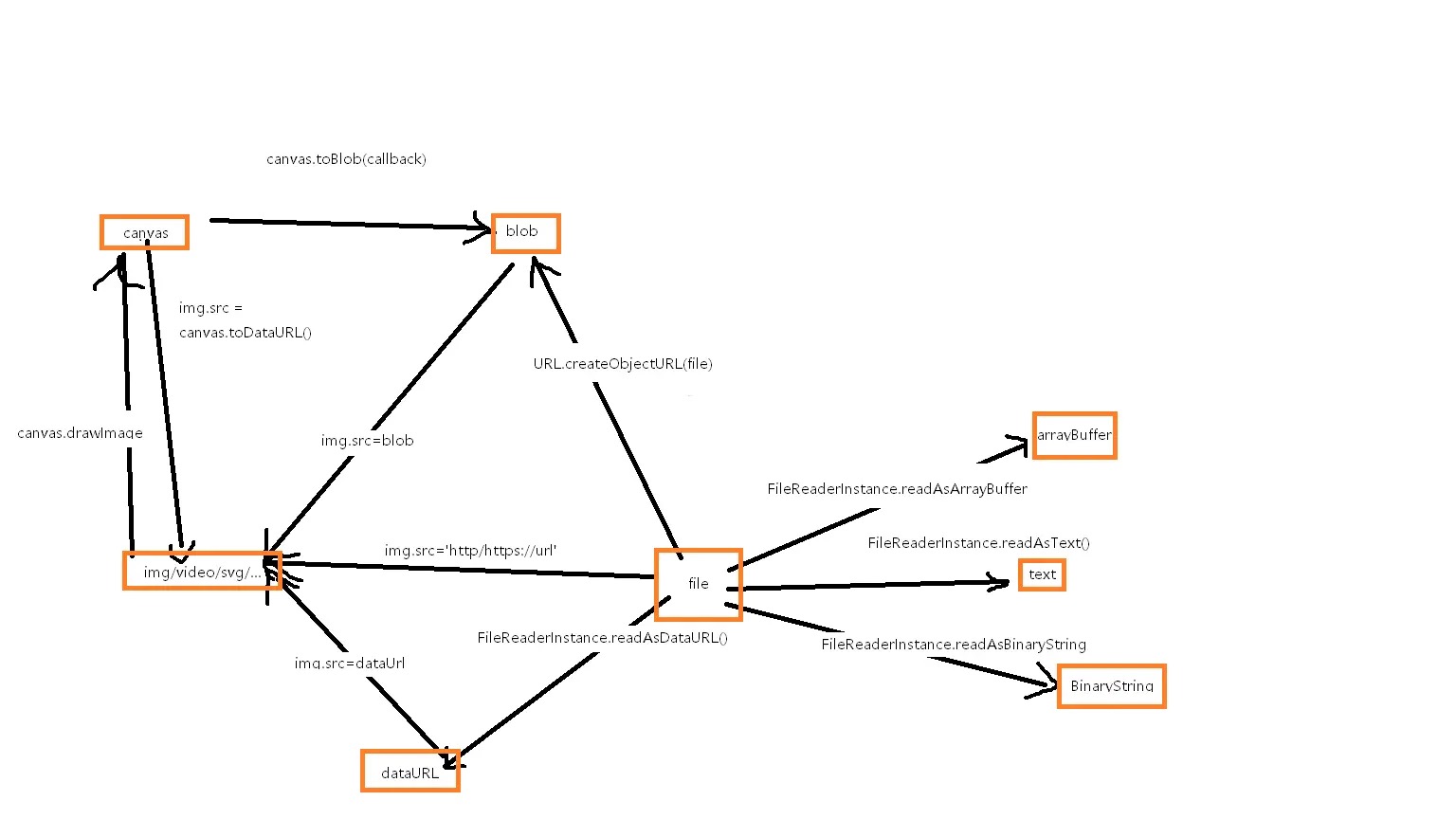
# blob、dataUrl、ArrayBuffer
# referrer
# 简介
- HTML
<meta>标签name="referrer"属性主要用于控制网页发送给服务器的 referrer 信息,可以告诉服务器端用户是从哪个页面来到当前网页的。也就是说 HTTP 请求报头中的 referrer 包含了跳转至当前页面的上一个页面的 url 地址; - 可以用来统计用户的来源,还可以用于分析用户的兴趣爱好、收集日志、优化缓存等等。
- 如果禁止 referrer,可以防止盗链,或也可以绕过防盗链,也能防范一些攻击。
- 在后台中使用了 referer 属性,会导致 js 和 php 的一些跳转出现问题,同时,也很有可能会导致一些第三方的统计代码失效,比如 cnzz,百度统计,解决方法是不用该属性,或者使用 iframe 包裹一层,用一个独立的 html 页面加载统计代码!
<meta name="referrer" content="no-referrer">由于需要跳转访问的页面带有网站访问限制,需要控制网页发送给服务器的 referrer 信息 设置为空,绕过 referer 鉴权检查。- 开启后需要配置白名单,以免影响正常的 SEO。
# referrer 属性写法
在 html 页面中的<head>头部区域用 meta 标签添加 referrer 属性,referrer 有五种属性:
- No Referrer (永远不做记录)
- No Referrer When Downgrade(浏览器默认,当降级时候不记录,从 https 跳转到 http)
- Origin Only(只记录 协议+ host)
- Origin When Cross-origin(仅在发生跨域访问时记录 协议+host)
- Unsafe URL(永远记录)
# 图片压缩网站 tinify
- https://tinypng.com/
- 也有一些专门用于压缩图片的库:
image-compressor、browser-image-compression、compressorjs等。
# 相等和严格相等:== 和 ===
- 相等(==)运算符检查其两个操作数是否相等,返回一个布尔值结果。与严格相等运算符不同,它会尝试转换不同类型的操作数,并进行比较。
- 严格相等(===)运算符检查其两个操作数是否相等,并且类型也相同,返回一个布尔值结果。它不会尝试转换数据类型,如果两个操作数类型不同,它将返回 false。
相等运算符的比较规则:
- 如果操作数具有相同的类型,则按如下方式进行比较:
- 对象(Object):仅当两个操作数引用同一个对象时返回 true。
- 字符串(String):仅当两个操作数具有相同的字符且顺序相同时返回 true。
- 数字(Number):如果两个操作数的值相同,则返回 true。+0 和 -0 被视为相同的值。如果任何一个操作数是 NaN,返回 false;所以,NaN 永远不等于 NaN。
- 布尔值(Boolean):仅当操作数都为 true 或都为 false 时返回 true。
- 大整型(BigInt):仅当两个操作数的值相同时返回 true。
- 符号(Symbol):仅当两个操作数引用相同的符号时返回 true。
Symbol('a')===Symbol('a');//false,Symbol('a')==Symbol('a');//false,Symbol.for('a')==Symbol.for('a');//true
- 如果其中一个操作数为 null 或 undefined,另一个操作数也必须为 null 或 undefined 以返回 true。否则返回 false。
- 如果其中一个操作数是对象,另一个是原始值,则将对象转换为原始值。
- 在这一步,两个操作数都被转换为原始值(字符串、数字、布尔值、符号和大整型中的一个)。剩余的转换将分情况完成。
- 如果是相同的类型,使用步骤 1 进行比较。
- 如果其中一个操作数是符号而另一个不是,返回 false。
- 如果其中一个操作数是布尔值而另一个不是,则将布尔值转换为数字:true 转换为 1,false 转换为 0。然后再次对两个操作数进行宽松比较。
- 数字与字符串:将字符串转换为数字。转换失败将导致 NaN,这将保证相等比较为 false。
- 数字与大整型:按数值进行比较。如果数字的值为 ±∞ 或 NaN,返回 false。
- 字符串与大整型:使用与 BigInt() 构造函数相同的算法将字符串转换为大整型数。如果转换失败,返回 false。
- 宽松相等是对称的:A == B 对于 A 和 B 的任何值总是具有与 B == A 相同的语义(应用转换的顺序除外)。
- 该运算符与严格相等(===)运算符之间最显著的区别是,严格相等运算符不尝试类型转换。相反,严格相等运算符总是认为不同类型的操作数是不同的。严格相等运算符本质上只执行第 1 步,然后对所有其他情况返回 false。
- 上面的算法有一个“故意违反”:如果其中一个操作数是 document.all,则它被视为 undefined。这意味着
document.all == null是true,但document.all === undefined&&document.all === null都是false。
# Number 双精度浮点数 64bit
js 采用 IEEE754 标准中的 双精度浮点数来表示一个数字,标准规定双精度浮点数采用 64 位存储,即 8 个字节表示一个浮点数。

在双精度浮点数中,第一位的 1bit 符号位 决定了这个数的正负,指数部分的 11bit 决定数值大小,小数部分的 52bit 决定数值精度。
# 数值范围
指数部分为 11bit 也就是 2^11 - 1 = 2047,取中间值进行偏移得到 [-1023, 1024],因此这种存储结构能够表示的数值范围为 2^-1023 至 2^1024,超出这个范围无法表示。转换为科学计数法为:
2^-1023 = 5 × 10^-324;
2^1024 = 1.7976931348623157 × 10^308;
Number.MAX_VALUE; // 1.7976931348623157e+308
Number.MIN_VALUE; // 5e-324
2
3
4
5
# 安全整数
IEEE754 规定,有效数字第一位默认总是 1,但它不保存在 64 位浮点数之中。所以有效数字为 52bit + 1 = 53bit。
这意味着 js 能表示并进行精确算术运算的安全整数范围为 [-2^53 -1, 2^53 - 1] 即 -9007199254740991 到最大值 9007199254740991 之间的范围。
Math.pow(2, 53) - 1; // 9007199254740991
-Math.pow(2, 53) - 1; // -9007199254740991
console.log(Number.MAX_SAFE_INTEGER); // 9007199254740991
console.log(Number.MIN_SAFE_INTEGER); // -9007199254740991
2
3
4
5
对于超过这个安全整数的运算,需要使用 BigInt 来计算。
console.log(9007199254740991 + 2); // 9007199254740992
console.log(BigInt(9007199254740991) + BigInt(2)); // 9007199254740993n
2
# 精度丢失问题 0.1+0.2 !== 0.3 ?
0.1 和 0.2 在转换为二进制时由于做了 0 舍 1 入 ,发生了一次精度丢失,而对于计算后的二进制又做了一次 0 舍 1 入再产生一次精度丢失,因此得到的结果是不准确的。解决方法是使用 Number.EPSILON,只要两个值的差小于 Number.EPSILON,就认为二者相等。
# 四舍五入
- Math.round(number) 方法无法对小数进行计算
- Number.toFixed() 方法实际上采用四舍六入五成双的规则实现,存在一些缺陷:"四舍六入五成双"含义:对于位数很多的近似数,当有效位数确定后,其后面多余的数字应该舍去,只保留有效数字最末一位,这种修约(舍入)规则是“四舍六入五成双”,也即“4 舍 6 入 5 凑偶”这里“四”是指 ≤4 时舍去,"六"是指 ≥6 时进上,"五"指的是根据 5 后面的数字来定,当 5 后有数时,舍 5 入 1;当 5 后无有效数字时,需要分两种情况来讲:5 前为奇数,舍 5 入 1;5 前为偶数,舍 5 不进(0 是偶数)。这种修约规则是为了减少舍入误差,提高舍入精度。注意输出的是字符串。
一种自定义的 toFixed 方法:
// 四舍五入
export const toFixed = function (number, decimalLength = 0) {
var times = Math.pow(10, decimalLength);
var fixed = number * times + 0.5;
return parseInt(fixed) / times;
};
2
3
4
5
6
toFixed 示例:接受一个整数参数 digits,表示小数点后要保留的位数。
(1.255).toFixed(2);
// '1.25'
1.2550.toFixed(2);
// '1.25'
1.2551.toFixed(2);
// '1.26'
1.2549.toFixed(2)
// '1.25'
1.1549.toFixed(2)
// '1.15'
(1.254).toFixed(2);
// '1.25'
(1.256).toFixed(2);
// '1.26'
(1.155).toFixed(2);
// '1.16'
(1.154).toFixed(2);
// '1.15'
(1.156).toFixed(2);
// '1.16'
// Precision看起来和toFixed差不多
1.255.toPrecision(3)
// '1.25'
1.2551.toPrecision(3)
// '1.26'
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
# parseInt
- 不建议使用 parseInt,应该使用 Number 来转换 string 到数字
Number()和parseInt有什么区别呢?
Number(string)函数评估整个字符串并将其转换为数字,如果这个字符串不是一个数字,就返回 NaN。- 而
parseInt(string, [radix])会尝试在传递的字符串中找到第一个数字,将其转换为传递的基数,默认为10,只有在找不到任何数字时才会返回NaN。 - 这意味着如果你传递一个像
5e2这样的字符串,那么,parseInt会在看到e时停止,因此只返回5,而Number则评估整个字符串并返回正确的值500。 Number性能优于parseInt- 在某些用例中使用
parseInt是有益的,比如你想从浮点数中推断出一个整数,那么parseInt比Math.round()快 50%。 - 如果你想将一个带有像素的字符串转换为数字,比如
32px转换为32,那么你应该使用parseInt,但大多数时候你最好还是使用Number。 - 如果你想将数字从十进制系统转换为其他进制的数字,也可以用
parseInt。 - 除非在某些特定情况下,parseInt 能返回你所需要的东西而 Number 不能,那才选择 parseInt。在 99%的用例中,你最好还是选择 Number。
- 为什么 parseInt(0.0000005) === 5 ?
- 传入字符串
'0.0000005'时,一切正常,得到 0 - 实际上,parseInt 的第一个参数如果不是一个字符串,则将其转换为字符串(使用 ToString 抽象操作),意思就是说:parseInt 会将参数自动转换成字符串,再去做取整操作
- 将浮点数手动转换为字符串:
String(0.000005); // => '0.000005' - 将浮点数手动转换为字符串:
String(0.0000005); // => '5e-7' parseInt(0.0000005); // => 5parseInt(5e-7); // => 5parseInt('5e-7'); // => 5parseInt()总是将其第一个参数转换为字符串,所以小于10e-6的浮点数将以指数表示法编写。然后parseInt()从 float 的指数表示法中提取整数!- 为了安全地提取浮点数的整数部分,建议使用
Math.floor()函数:Math.floor(0.0000005); // => 0 parseInt(999999999999999999999)等于 1,原因同上。
# Boolean
在 js 中所有类型的值都能转换成 Boolean 值。通过 Boolean 转换时:
- 除了空字符串意外,其他字符串都为 true
- 除了 0 与 NaN,其他数字都为 true
- undefined => false
- Symbol() => true
- null => false
- 所有引用类型都为 true,不管是[]还是{}
# 为什么 typeof null 会被判断为 object
在 JS 中。数据在底层都是以二进制储存,引用类型的二进制前三位为 0,typeof 是根据这个特性来进行判断类型的工作,可这里有一个问题就是,null 类型所有位数都为 0,所以它的前三位也为 0 ,所以 null 会被判断为 object。
# Object
- 栈内存-用来储存基本类型,以及引用类型的指针,堆内存-用来储存引用类型数据。
- 深拷贝:
JSON.parse(JSON.stringify())。 - 浅拷贝:
Object.assign(),只能拷贝第一层属性,如果第一层属性是个对象,那么会拷贝这个对象的引用。
# 继承
例子:
function Animal(type) {
this.type = type;
}
Animal.prototype.getType = function () {
return this.type;
};
function People(name) {
Animal.call(this, "people"); // 继承属性type
this.name = name; // 自己的属性name
}
People.prototype = Object.create(Animal.prototype); // 继承方法getType及原型
People.prototype.getName = function () {
// 定义自己的方法
return this.name;
};
const human = new People("Eric"); // 生成实例
human.getName(); // 'Eric'
human.getType(); // 'people'
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
# IndexDB
// IDBOpenDBRequest 表示打开数据库的请求
const request = indexedDB.open( 'people', version );
// 版本更新,创建新的store的时候
request.onupgradeneeded = ( event ) => {
// IDBDatabase 表示与数据库的连接。这是获取数据库事务的唯一方法。
const db = event.target.result;
if(!db.objectStoreNames.contains(stroeName)) {
db.createObjectStore(stroeName, {keyPath: 'key'} );
}
openSuccess(db);
};
request.onsuccess = ( event ) => {
// IDBDatabase 表示与数据库的连接。这是获取数据库事务的唯一方法。
const db = event.target.result;
openSuccess(db);
};
request.onerror = ( event ) => {
console.error( 'IndexedDB', event );
};
// IDBOpenDBRequest 表示打开数据库的请求
Const Request=indexedDB.open("People", Version);
// 版本更新,创建新的store的时候
Request.onUpgradeneded=(e)=>{
// IDBDatabase 表示与数据库的连接。这是获取数据库事务的唯一方法。
Const db=event.Target.result;
if(db.objectStoreNames.include(StroeName) === false){
Db.createObjectStore(stroeName, {keyPath: 'key'});
}
OpenSuccess(DB);
};
Request.onSuccess=(e)=>{
// IDBDatabase 表示与数据库的连接。这是获取数据库事务的唯一方法。
const db=event.Target.result;
OpenSuccess(DB);
};
Request.onError=(e)=>{
合并错误("IndexedDB",e);
};
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
# JavaScript
# 闭包
在 JavaScript 中,根据词法作用域的规则,内部函数总是可以访问其外部函数中声明的变量,当通过调用一个外部函数返回一个内部函数后,即使该外部函数已经执行结束了,但是内部函数引用外部函数的变量依然保存在内存中,我们就把这些变量的集合称为闭包。比如外部函数是 foo,那么这些变量的集合就称为 foo 函数的闭包。
使用闭包的时候,你要尽量注意一个原则:如果该闭包会一直使用,那么它可以作为全局变量而存在;但如果使用频率不高,而且占用内存又比较大的话,那就尽量让它成为一个局部变量。
通常,如果引用闭包的函数是一个全局变量,那么闭包会一直存在直到页面关闭;但如果这个闭包以后不再使用的话,就会造成内存泄漏。
如果引用闭包的函数是个局部变量,等函数销毁后,在下次 JavaScript 引擎执行垃圾回收时,判断闭包这块内容如果已经不再被使用了,那么 JavaScript 引擎的垃圾回收器就会回收这块内存。
# 闭包导致内存泄漏
- 持有本该被销毁的函数,造成其关联的词法环境无法销毁,导致无法被 GC,造成内存泄漏。
- 当有多个函数共享一个词法环境时,可能导致词法环境膨胀,从而发生无法访问但又无法销毁的数据,造成内存泄漏。
# 词法作用域
词法作用域就是指作用域是由代码中函数声明的位置来决定的,所以词法作用域是静态的作用域,通过它就能够预测代码在执行过程中如何查找标识符。注意这里是和“声明”而不是“调用”的位置有关,所以才是静态的。
JavaScript 语言的作用域链是由词法作用域决定的,而词法作用域是由代码结构来确定的。
# 变量提升
块级作用域就是通过词法环境的栈结构来实现的,而变量提升是通过变量环境来实现,通过这两者的结合,JavaScript 引擎也就同时支持了变量提升和块级作用域了。
函数内部通过 var 声明的变量,在编译阶段全都被存放到变量环境里面了。
通过 let 声明的变量,在编译阶段会被存放到词法环境(Lexical Environment)中。
在函数的作用域块内部,通过 let 声明的变量并没有被存放到词法环境中,而是等到作用域执行时,被以一个单独的块的形式放入词法环境的栈结构顶部。
在词法环境内部,维护了一个小型栈结构,栈底是函数最外层的变量,进入一个作用域块后,就会把该作用域块内部的变量压到栈顶;当作用域执行完成之后,该作用域的信息就会从栈顶弹出,这就是词法环境的结构。需要注意下,我这里所讲的变量是指通过 let 或者 const 声明的变量。
当访问某个变量时,会先从当前对应的执行上下文的词法环境的栈顶向栈底依次查找,如果没有则去变量环境中查找,(如果还没有则去全局执行上下文找),否则返回 undefined。
# 性能优化
对于优化 JavaScript 执行效率,你应该将优化的中心聚焦在单次脚本的执行时间和脚本的网络下载上,主要关注以下三点内容:提升单次脚本的执行速度,避免 JavaScript 的长任务霸占主线程,这样可以使得页面快速响应交互;避免大的内联脚本,因为在解析 HTML 的过程中,解析和编译也会占用主线程;减少 JavaScript 文件的容量,因为更小的文件会提升下载速度,并且占用更低的内存。
# 计算机网络模型

# 输入 URL 到页面展示的过程
# 过程
- 用户输入 URL,浏览器会根据用户输入的信息判断是搜索还是网址,如果是搜索内容,就将搜索内容+默认搜索引擎合成新的 URL;如果用户输入的内容符合 URL 规则,浏览器就会根据 URL 协议,在这段内容上加上协议合成合法的 URL
- 用户输入完内容,按下回车键,浏览器导航栏显示 loading 状态,但是页面还是呈现前一个页面,这是因为新页面的响应数据还没有获得
- 浏览器进程浏览器构建请求行信息,会通过进程间通信(IPC)将 URL 请求发送给网络进程 GET /index.html HTTP1.1
- 网络进程获取到 URL,先去本地缓存中查找是否有缓存文件,如果有,拦截请求,直接 200 返回;否则,进入网络请求过程
- 网络进程请求 DNS 返回域名对应的 IP 和端口号,如果之前 DNS 数据缓存服务缓存过当前域名信息,就会直接返回缓存信息;否则,发起请求获取根据域名解析出来的 IP 和端口号,如果没有端口号,http 默认 80,https 默认 443。如果是 https 请求,还需要建立 TLS 连接。
- Chrome 有个机制,同一个域名同时最多只能建立 6 个 TCP 连接,如果在同一个域名下同时有 10 个请求发生,那么其中 4 个请求会进入排队等待状态,直至进行中的请求完成。如果当前请求数量少于 6 个,会直接建立 TCP 连接。
- TCP 三次握手建立连接,http 请求加上 TCP 头部——包括源端口号、目的程序端口号和用于校验数据完整性的序号,向下传输
- 网络层在数据包上加上 IP 头部——包括源 IP 地址和目的 IP 地址,继续向下传输到底层
- 底层通过物理网络传输给目的服务器主机
- 目的服务器主机网络层接收到数据包,解析出 IP 头部,识别出数据部分,将解开的数据包向上传输到传输层
- 目的服务器主机传输层获取到数据包,解析出 TCP 头部,识别端口,将解开的数据包向上传输到应用层
- 应用层 HTTP 解析请求头和请求体,如果需要重定向,HTTP 直接返回 HTTP 响应数据的状态 code301 或者 302,同时在请求头的 Location 字段中附上重定向地址,浏览器会根据 code 和 Location 进行重定向操作;如果不是重定向,首先服务器会根据 请求头中的 If-None-Match 的值来判断请求的资源是否被更新,如果没有更新,就返回 304 状态码,相当于告诉浏览器之前的缓存还可以使用,就不返回新数据了;否则,返回新数据,200 的状态码,并且如果想要浏览器缓存数据的话,就在相应头中加入字段: Cache-Control:Max-age=2000 响应数据又顺着应用层——传输层——网络层——网络层——传输层——应用层的顺序返回到网络进程
- 数据传输完成,TCP 四次挥手断开连接。如果,浏览器或者服务器在 HTTP 头部加上如下信息,TCP 就一直保持连接。保持 TCP 连接可以省下下次需要建立连接的时间,提示资源加载速度 Connection:Keep-Alive
- 网络进程将获取到的数据包进行解析,根据响应头中的 Content-type 来判断响应数据的类型,如果是字节流类型,就将该请求交给下载管理器,该导航流程结束,不再进行;如果是 text/html 类型,就通知浏览器进程获取到文档准备渲染
- 浏览器进程获取到通知,根据当前页面 B 是否是从页面 A 打开的并且和页面 A 是否是同一个站点(根域名和协议一样就被认为是同一个站点),如果满足上述条件,就复用之前网页的进程,否则,新创建一个单独的渲染进程
- 浏览器会发出“提交文档”的消息给渲染进程,渲染进程收到消息后,会和网络进程建立传输数据的“管道”,文档数据传输完成后,渲染进程会返回“确认提交”的消息给浏览器进程
- 浏览器收到“确认提交”的消息后,会更新浏览器的页面状态,包括了安全状态、地址栏的 URL、前进后退的历史状态,并更新 web 页面,此时的 web 页面是空白页
- 渲染进程对文档进行页面解析和子资源加载,HTML 通过 HTML 解析器转成 DOM Tree(二叉树类似结构的东西),CSS 按照 CSS 规则和 CSS 解释器转成 CSSOM TREE,两个 tree 结合,形成 render tree(不包含 HTML 的具体元素和元素要画的具体位置),通过 Layout 可以计算出每个元素具体的宽高颜色位置,结合起来,开始绘制,最后显示在屏幕中新页面显示出来
- 在域名解析的过程中会有多级的缓存,浏览器首先看一下自己的缓存里有没有,如果没有就向操作系统的缓存要,还没有就检查本机域名解析文件 hosts,也就是上一讲中我们修改的
C:\WINDOWS\system32\drivers\etc\hosts
# 渲染过程
渲染过程:
总结:
# 如何减少重排重绘
- 集中修改样式或直接切换 class 操作样式,而不是频繁操作 style
- 避免使用 table 布局或者 float 等布局,推荐使用 flex 或 grid 等现代布局
- 批量 dom 操作,例如 createDocumentFragment,或者使用框架,例如 React
- Debounce window resize scroll 事件,频繁触发使用节流和防抖
- 对 dom 属性的读写要分离:在一个操作过程中,先完成所有的“读”操作,再完成所有的“写”操作,避免交替进行。读:获取 DOM 的属性值(如 offsetWidth、clientHeight、scrollTop 等)。写:修改 DOM 的属性值(如设置 style.width、innerHTML 等)。如果在代码中,读写 DOM 操作是交替进行的,可能会触发浏览器多次的重排,降低性能。
will-change: transform做优化- 修改之前先设置
display:none,脱离文档流,修改完了再恢复 - 使用 BFC 特性,不影响其他元素
- 减少复杂选择器,避免深层嵌套 CSS 选择器,减少样式计算时间
- 优化动画,使用 css3 的 transform(直接在非主线程上执行合成动画操作) 和 requestAnimationFrame 来实现动画效果
- 使用 opacity 替代 visibility,硬件加速:transform,opacity,filter,will-change,backface-visibility,perspective,clip-path 等
- 限制重绘范围,使用 CSS Containment 隔离重绘:
.container {contain: paint; /* 限制重绘区域 */} - 使用 debounce 或 throttle 控制高频操作
减少重排重绘,相当于少了渲染进程的主线程和非主线程的很多计算和操作,能够加快 web 的展示。
- 触发 repaint、reflow 的操作尽量放在一起,比如改变 dom 高度和设置 margin 分开写,可能会触发两次重排;
- 通过虚拟 dom 层计算出操作总的差异,一起提交给浏览器。之前还用过 document.createDocumentFragment 来汇总 append 的 dom,来减少触发重排重绘次数。
重排一定导致重绘:width、height、margin、font-size
重绘不一定触发重排:color、background、opacity
# ECharts 简介
ECharts 支持以 Canvas、SVG(4.0+)、VML 的形式渲染图表。VML 可以兼容低版本 IE,SVG 使得移动端不再为内存担忧,Canvas 可以轻松应对大数据量和特效的展现。不同的渲染方式提供了更多选择,使得 ECharts 在各种场景下都有更好的表现。底层依赖矢量图形库 ZRender,可以流畅的运行在 PC 和移动设备上,兼容当前绝大部分浏览器。
除了 PC 和移动端的浏览器,ECharts 还能在 node 上配合 node-canvas 进行高效的服务端渲染(SSR)。从 4.0 开始还和微信小程序的团队合作,提供了 ECharts 对微信小程序的适配!
通过增量渲染技术(4.0+),配合各种细致的优化,ECharts 能够展现千万级的数据量,并且在这个数据量级依然能够进行流畅的缩放平移等交互。几千万的地理坐标数据就算使用二进制存储也要占上百 MB 的空间。因此 ECharts 同时提供了对流加载(4.0+)的支持,你可以使用 WebSocket 或者对数据分块后加载,加载多少渲染多少!不需要漫长地等待所有数据加载完再进行绘制。
交互是从数据中发掘信息的重要手段。“总览为先,缩放过滤按需查看细节”是数据可视化交互的基本需求。ECharts 一直在交互的路上前进,我们提供了 图例、视觉映射、数据区域缩放、tooltip、数据刷选等开箱即用的交互组件,可以对数据进行多维度数据筛取、视图缩放、展示细节等交互操作。
ECharts 3 开始加强了对多维数据的支持。除了加入了平行坐标等常见的多维数据可视化工具外,对于传统的散点图等,传入的数据也可以是多个维度的。配合视觉映射组件 visualMap 提供的丰富的视觉编码,能够将不同维度的数据映射到颜色、大小、透明度、明暗度等不同的视觉通道。
ECharts 由数据驱动,数据的改变驱动图表展现的改变。因此动态数据的实现也变得异常简单,只需要获取数据,填入数据,ECharts 会找到两组数据之间的差异然后通过合适的动画去表现数据的变化。配合 timeline 组件能够在更高的时间维度上去表现数据的信息。
通过基于 WebGL 的 ECharts GL,可以跟使用 ECharts 普通组件一样轻松的使用 ECharts GL 绘制出三维的地球,建筑群,人口分布的柱状图,实现更多更强大绚丽的三维可视化效果。
# 在 ECharts 中进行降采样,以渲染大批量数据
在 ECharts 中处理和渲染大批量数据时,降采样(Downsampling)是一个非常关键的性能优化手段。它的核心思想是在保持数据整体趋势和特征的前提下,减少需要渲染的数据点的数量,从而显著提高图表的渲染速度和交互流畅性。
ECharts 内置了对数据降采样的支持,主要通过在 series 中配置 sampling 属性来实现。在数据量远大于像素点时候的降采样策略,开启后可以有效的优化图表的绘制效率,默认关闭,也就是全部绘制不过滤数据点,有:lttb/average/min/max/minmax/sum 等取值,分别对应不同的采样策略。比如折线图的降采样设置 (opens new window)
option = {
// ... 其他配置 ...
series: [
{
type: "line", // 或者 'scatter', 'candlestick' 等支持采样的图表类型
data: yourLargeDataArray, // 你的原始大数据数组
sampling: "lttb", // 或者 'average', 'max', 'min', 'sum'
},
],
// ... 其他配置 ...
};
2
3
4
5
6
7
8
9
10
11
一些常规的思路:
- 简单抽样:对于数据集,可以通过随机选择一部分数据点来实现简单的降采样。
- 聚合方法:对于数据点,可以使用聚合方法(如平均值、最大值、最小值)来减少点的数量。例如,可以把多个数据点聚合成一个点。
- 使用数据缩放:在用户缩放或平移图表时,可以动态调整展示的数据量。例如使用 ECharts 的 dataZoom 功能来控制显示。
- 使用 setOption 动态更新:根据当前视口的变化,动态更新需要渲染的数据点。通过监听数据缩放和移动事件,获取当前的可视范围。
- 使用 Web Worker:如果数据量非常大,可以考虑使用 Web Worker 来处理降采样。这种方法可以在后台线程中进行数据处理,避免阻塞主线程。
# 负载均衡
# 什么是负载均衡?
负载均衡(Load Balancing)是一种计算技术,它的主要目的是将网络流量、工作负载或计算请求有效地分配到多个服务器、计算资源或网络链路上。想象一下,一个热门网站突然涌入大量用户,如果只有一个服务器来处理所有请求,服务器很可能会不堪重负,导致响应缓慢甚至崩溃。负载均衡通过引入一个“调度员”(负载均衡器),将这些请求分发给后端的多个服务器,从而避免单点故障,提高系统的可用性、可靠性和整体性能。
# 为什么需要负载均衡?
- 提高可用性(High Availability):当后端某台服务器发生故障时,负载均衡器会自动将流量切换到其他健康的服务器上,保证服务的持续可用。
- 提升性能和吞吐量(Improved Performance & Throughput):通过将请求分发到多个服务器,可以并行处理更多请求,减少用户等待时间,提升整体处理能力。
- 增强可扩展性(Scalability):当业务增长,请求量增加时,可以方便地向服务器集群中添加新的服务器,而无需中断服务。负载均衡器会自动将新服务器纳入工作范围。
- 降低单点故障风险(Reduced Single Point of Failure):避免了所有压力都集中在一台服务器上,即使个别服务器出现问题,整个系统依然可以运行。
- 简化维护(Simplified Maintenance):在需要对某台服务器进行维护或升级时,可以先将其从负载均衡池中移除,待维护完成后再重新加入,整个过程对用户透明,不影响服务。
# 常用的负载均衡模式(算法)
负载均衡器使用不同的算法(或称为模式、策略)来决定如何将传入的请求分配给后端服务器。
# 轮询(Round Robin)
- 工作原理:这是最简单且最常用的负载均衡算法。负载均衡器按顺序将每个新的连接请求依次分配给后端服务器列表中的下一台服务器。当到达列表末尾时,它会重新从列表的开头开始。
- 详细介绍:
- 优点:实现简单,配置方便,成本低。在所有后端服务器配置和性能都相似,并且每个请求处理时间也相近的情况下,轮询可以很好地平均分配负载。
- 缺点:它不考虑后端服务器当前的实际负载情况或连接数。如果某些服务器性能较弱或正在处理耗时较长的请求,可能会导致这些服务器过载,而其他服务器可能仍然空闲。
- 适用场景:适用于后端服务器性能相似,且请求处理时间相对均匀的场景。
# 加权轮询(Weighted Round Robin)
- 工作原理:这是轮询算法的改进版本。管理员可以为每台后端服务器分配一个权重值。权重越高的服务器,接收到的连接请求比例就越大。例如,如果服务器 A 的权重是 3,服务器 B 的权重是 1,那么在每 4 个新连接中,服务器 A 会处理 3 个,服务器 B 会处理 1 个。
- 详细介绍:
- 优点:能够根据服务器的实际处理能力分配请求,性能更强的服务器可以承担更多的负载。
- 缺点:权重的设置需要管理员根据服务器性能进行评估和调整。如果权重设置不当,或者服务器的实际负载情况动态变化较大,仍然可能出现负载不均的情况。它仍然不考虑服务器当前的实时连接数或响应时间。
- 适用场景:适用于后端服务器性能存在差异的场景。
# 最少连接(Least Connections)
- 工作原理:负载均衡器会跟踪每台后端服务器当前的活动连接数。当有新的连接请求到达时,负载均衡器会将请求分配给当前活动连接数最少的服务器。
- 详细介绍:
- 优点:这是一种动态的负载均衡算法,能够根据服务器的实时负载情况(以连接数衡量)来分配请求,使得负载更加均衡,尤其适用于请求处理时间差异较大的场景。
- 缺点:实现比轮询复杂,需要维护后端服务器的连接数状态。
- 适用场景:适用于后端服务器处理请求的时长可能差异较大,或者服务器性能不一的场景,能够有效地避免某些服务器连接过多。
# 加权最少连接(Weighted Least Connections)
- 工作原理:这是最少连接算法和加权思想的结合。服务器不仅有权重,负载均衡器在选择服务器时,会综合考虑服务器的权重和当前的活动连接数。通常的计算方式是 活动连接数 / 权重,选择结果值最小的服务器。
- 详细介绍:
- 优点:在最少连接的基础上,进一步考虑了服务器的处理能力差异,是更为精细和公平的分配策略。
- 缺点:实现更为复杂,需要同时维护连接数和权重信息。
- 适用场景:适用于后端服务器性能和处理能力有显著差异,并且希望根据实时连接数和服务器能力进行动态分配的复杂场景。
# IP 哈希(IP Hash / Source IP Hash)
- 工作原理:负载均衡器根据请求的源 IP 地址进行哈希计算,然后根据哈希结果将请求分配给固定的后端服务器。这意味着来自同一个客户端(同一个 IP 地址)的请求通常会被定向到同一台后端服务器。
- 详细介绍:
- 优点:可以实现会话保持(Session Persistence)。对于某些需要用户会话状态(如购物车、登录状态)的应用非常有用,因为用户的多次请求都会落到同一台服务器上,服务器可以方便地维护该用户的会话信息。
- 缺点:如果客户端 IP 地址分布不均(例如,大量用户通过同一个代理服务器访问),可能会导致某些后端服务器负载过高,而其他服务器负载较低。如果某台后端服务器宕机,那么分配到该服务器的客户端会话可能会丢失或需要重新建立。
- 适用场景:需要会话保持的应用,例如电商网站的购物车、需要登录状态的在线服务等。
# URL 哈希(URL Hash)
- 工作原理:与 IP 哈希类似,但它是根据请求的 URL 进行哈希计算,然后将特定 URL 的请求定向到固定的后端服务器。
- 详细介绍:
- 优点:可以将特定类型的请求(例如,图片请求、视频请求、API 请求)定向到专门处理这类请求的服务器集群,从而提高缓存效率和处理效率。
- 缺点:配置相对复杂,需要对 URL 结构有清晰的规划。
- 适用场景:适用于大型网站,希望将不同类型的静态或动态内容分发到不同的后端服务器集群以优化性能和缓存的场景。
# 最快响应时间(Least Response Time)
- 工作原理:负载均衡器会定期向后端服务器发送健康检查请求(例如一个简单的 HTTP GET 请求),并记录每台服务器的响应时间。当有新的连接请求到达时,它会选择当前平均响应时间最短的服务器。
- 详细介绍:
- 优点:能够根据服务器的真实响应能力来分配请求,确保用户获得最快的服务。
- 缺点:实现比较复杂,需要持续监控服务器的响应时间,这会给负载均衡器本身带来一定的开销。响应时间的波动可能会导致请求分配的抖动。
- 适用场景:对用户响应时间要求极高的应用。
# 负载均衡的实现层面
- DNS 负载均衡 (L3/L4):通过 DNS 解析将同一个域名解析到不同的 IP 地址(对应不同的服务器)。优点是实现简单、成本低。缺点是生效慢(DNS 缓存),且无法感知后端服务器的实际健康状况,故障切换延迟大,因为会受到运营商 DNS 缓存的影响,流量调度策略简单,支持的算法少-RR。先通过 DNS 实现地理级别的负载均衡,再通过下层的更专业的负载均衡设备实现具体的细节。
- 硬件负载均衡器 (L4/L7):专用的硬件设备,如 F5 BIG-IP,A10,Citrix NetScaler。性能高,功能强大,支持复杂的策略,但价格昂贵。
- L4 (传输层):基于 IP 地址和端口号进行转发,不关心应用层的内容。速度快,效率高。常见的有基于 TCP/UDP 的负载均衡。
- L7 (应用层):可以理解 HTTP 报文内容,根据 URL、HTTP 头部、Cookie 等信息进行更智能的负载均衡和流量控制。功能更丰富,但处理速度相对 L4 慢。
- 软件负载均衡器 (L4/L7):在通用服务器上运行的软件,如 Nginx, HAProxy, LVS (Linux Virtual Server)。成本较低,部署简单,配置灵活,方便进行扩展和定制功能,性能也足以满足大部分应用场景。
- Nginx:常用于 HTTP/HTTPS 负载均衡(L7),也可以做 TCP/UDP 负载均衡(L4)。反向代理功能强大。
- HAProxy:高性能的 TCP/HTTP 负载均衡器(L4/L7)。
- LVS:运行在 Linux 内核层,主要做 L4 负载均衡,性能极高。开源的。LVS+keepalived
- LVS 的三种工作方式:
client <==> DirectorServer(LVS installed) <==> RealServer- NAT:网络地址翻译。基于 IPVS 技术把 VIP 转换成 RIP 实现访问。后端服务器无需暴露真实 IP,但是负载均衡器需处理双向流量,容易成为性能瓶颈。
- DR 模式:直接路由技术。DirectorServer 和 RealServer 需要在同一广播域即同一台交换机上。仅请求流量经过负载均衡器,响应流量直达客户端,性能极高。
- TUN 模式:IP 隧道技术。支持跨机房部署,但隧道封装解封装带来额外开销,RealServer 需支持隧道协议,且需配置 VIP