# 设计模式
# 工厂模式
生成一个函数,return 一个实例,每次需要生成实例的时候直接调这个函数即可,而不需要 new。
# 单例模式
生成一个全局唯一的实例且不能生成第二个,比如 Redux、Vuex 的 store 或者全局唯一的 dialog、modal 等。例:js 是单线程的,创建单例很简单
class SingleTon {
private static instance: SingleTon | null = null;
private constructor() {}
public static getInstance(): SingleTon {
if (this.instance === null) {
this.instance = new SingleTon();
}
return this.instance;
}
fn1() {}
fn2() {}
}
const sig = SingleTon.getInstance();
sig.fn1();
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# 代理模式
Proxy:在对象之间架设一个拦截层,对一些操作进行拦截和处理。
# 观察者模式
一个主题,一个观察者,主体变化后触发观察者执行:btn.addEventListener('click',()=>{...}),Subject 和 Observer 直接绑定,没有中间媒介。
# 发布订阅模式
订阅/绑定一些事件eventBus.on('event1',()=>{});,然后发布/触发这些事件eventBus.emit('event1',props);,绑定的事件在组件销毁时记得删除解绑。Publisher 和 Observer 互不认识,需要中间媒介 Event Channel。
和观察者模式的区别: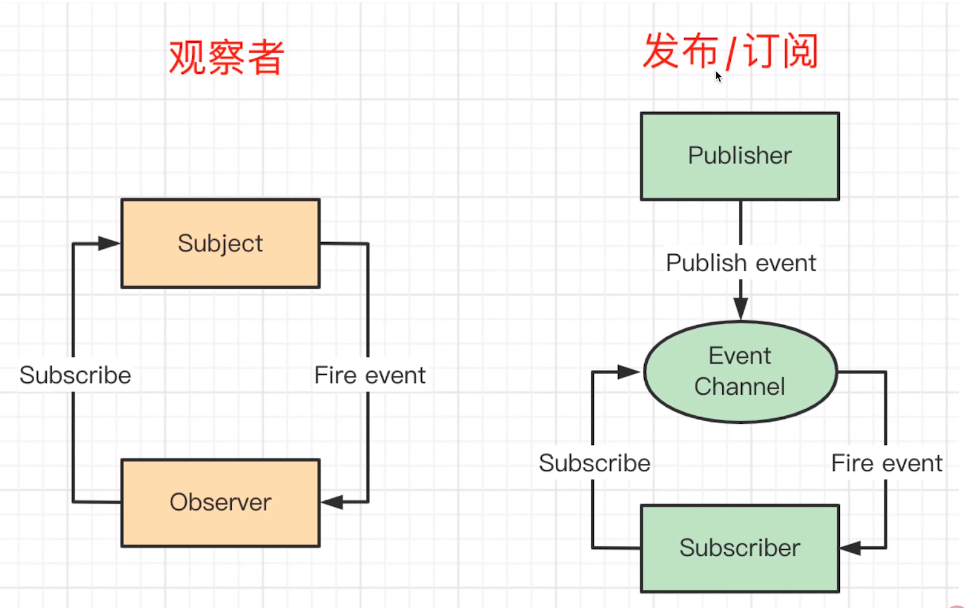
# 装饰器模式
Decorator:装饰类或者方法,不会修改原有的功能,只是增加一些新功能(AOP 面向切面编程)。
# 面试题
# addEventListener 和 onclick 事件的优先级
- 在事件发生时,所有通过 addEventListener 添加的处理函数都会先被调用(包括捕获阶段的处理函数),然后再调用 onclick 处理函数。
- addEventListener 可以添加多个处理函数,不会被覆盖。
- onclick 是单一的,后赋值会覆盖前一个。
# 手写 AST 的 demo
function add(a, b) {
return a + b;
}
// 转化为下面的AST代码
const ast = {
type: "Program",
body: [
{
type: "FunctionDeclaration",
id: {
type: "Identifier",
name: "add",
},
params: [
{
type: "Identifier",
name: "a",
},
{
type: "Identifier",
name: "b",
},
],
body: {
type: "BlockStatement",
body: [
{
type: "ReturnStatement",
argument: {
type: "BinaryExpression",
operator: "+",
left: {
type: "Identifier",
name: "a",
},
right: {
type: "Identifier",
name: "b",
},
},
},
],
},
},
],
sourceType: "script",
};
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
# 手写 VDOM 的 demo
const vdom = {
tag: "div",
attrs: { id: "app" },
children: [
{
tag: "h1",
attrs: null,
children: ["Hello, Virtual DOM!"],
},
{
tag: "p",
attrs: null,
children: ["This is a simple implementation."],
},
],
};
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# React 和 Vue 的虚拟 DOM 是怎么实现的
Vue 和 React 都使用虚拟 DOM(Virtual DOM)来提高渲染性能,但两者的实现细节和优化策略有所不同。
# Vue
- 虚拟 DOM 结构:Vue 的虚拟 DOM 节点(VNode)也是一个 JavaScript 对象,但包含更多优化字段。
- Diffing 算法:Vue 的 双端对比算法(SnabbDOM 优化版) 更高效:
- 同层比较:与 React 类似,按层级比较。
- 双端指针:对比列表时,同时从新旧列表的头、尾向中间扫描,减少移动操作。
- 静态标记:编译时标记静态节点(如 v-once),跳过 Diff 过程。
- 响应式驱动:虚拟 DOM 的更新由响应式系统自动触发,无需手动优化。
- 特点:
- 动静结合:通过模板编译时的静态分析,区分动态和静态节点,减少运行时比较。
- 组件级更新:每个组件维护自己的虚拟 DOM 树,更新时仅影响当前组件子树。
- 内置优化:无需手动实现 shouldComponentUpdate,Vue 的响应式系统自动追踪依赖。
# React
- 虚拟 DOM 结构:React 的虚拟 DOM 是一个轻量级的 JavaScript 对象(React Element),描述真实 DOM 的层级和属性。
- Diffing 算法:React 使用 递归的协调算法(Reconciliation) 比较新旧虚拟 DOM 树:
- 层级比较(Tree Diff):按树层级逐层对比,如果节点类型不同(如 div → span),直接销毁并重建整个子树。
- 列表优化(Keyed Diff):通过 key 属性识别列表元素的移动、插入或删除,减少不必要的操作。
- 批量更新:将多次状态更新合并为一次渲染(Batching),减少 DOM 操作次数。
- 特点:
- 不可变(Immutable):每次状态更新都会生成全新的虚拟 DOM 树。
- 全量 Diff:默认会递归比较整棵树(即使某些子树未变化),但开发者可通过 shouldComponentUpdate 或 React.memo 手动优化。
# 关键区别
| 特性 | React | Vue |
|---|---|---|
| 更新触发 | 状态变化后手动/自动生成新虚拟 DOM | 响应式数据变化自动触发更新 |
| Diff 范围 | 默认全量比较(可手动优化) | 自动跳过静态节点,局部比较 |
| 列表优化 | 依赖 key 的简单对比 | 双端对比 + key 优化 |
| 性能优化手段 | React.memo、useMemo 等 | 响应式自动追踪 + 编译时静态标记 |
| API 设计 | 推崇不可变性 | 拥抱可变数据 + 响应式 |
# 总结
- React:虚拟 DOM 是“纯运行时”优化,依赖开发者手动控制更新(如 key、React.memo)。
- Vue:结合模板编译时的静态分析和响应式系统,自动优化虚拟 DOM 的更新范围。
# render 函数
# React 的 render 函数
- 作用:
- 生成虚拟 DOM:将组件的状态(state/props)转换为虚拟 DOM 树(React Element 树),描述当前组件的 UI 结构。
- 触发时机:当组件的状态(state 或 props)变化时,React 会重新调用 render 函数。
- 纯函数特性:render 应该是纯函数(不直接修改状态或 DOM),仅根据输入返回输出。
- 输出结果:返回一个由
React.createElement()构建的轻量级 JavaScript 对象(虚拟 DOM)。 - 与渲染流程的关系:
- render 生成新的虚拟 DOM。
- React 通过 Diffing 算法 对比新旧虚拟 DOM。
- 将差异部分应用到真实 DOM(此过程称为 Reconciliation)。
- 目的:
- 声明式 UI:开发者只需关心“当前状态下的 UI 应该是什么样子”,而非如何手动更新 DOM。
- 性能优化:通过虚拟 DOM 减少直接操作真实 DOM 的开销。
# Vue 的 render 函数
- 作用:
- 生成虚拟 DOM:将组件的模板(或手写的 render 函数)转换为虚拟节点(VNode 树)。
- 触发时机:当响应式数据(data/props)变化时,Vue 的响应式系统会触发重新渲染。
- 与模板的关系:Vue 的模板最终会被编译为 render 函数(运行时或构建时)。
- 输出结果:返回一个由 createElement(即 h)构建的 VNode 对象。
- 与渲染流程的关系:
- render 生成新的 VNode 树。
- Vue 通过 Patch 算法 对比新旧 VNode。
- 高效更新真实 DOM。
- 目的:
- 灵活控制渲染逻辑:在需要动态生成复杂 UI 时,render 函数比模板更灵活(如动态渲染组件)。
- 性能优化:结合响应式系统和编译时优化(如静态节点提升),减少不必要的渲染。
# 区别对比
| 特性 | React | Vue |
|---|---|---|
| 触发条件 | 状态变化后必须重新执行 render | 响应式数据变化后自动触发 |
| 输入来源 | props + state | props + data + computed |
| 与模板的关系 | 无模板,JSX 直接编译为 render | 模板可选,编译为 render 函数 |
| 性能优化策略 | 依赖虚拟 DOM Diff | 响应式追踪 + 编译时静态分析 |
| 函数签名 | render() | render(h)(h 为 createElement) |
# 总结
- React 是“函数式”思维:render 是纯函数,UI 是状态的映射。每次更新都会重新生成整个虚拟 DOM 树,通过 Diff 算法找出最小变更。开发者控制优化:需手动使用 React.memo、useMemo 避免不必要的 render。核心是 “重新生成虚拟 DOM”,强调不可变性和显式更新,性能优化依赖开发者控制。
- Vue 是“响应式”思维:render 由响应式系统自动调度,仅重新渲染依赖变化的组件。自动化优化:通过模板编译时的静态标记(如 v-once)和响应式依赖追踪,减少不必要的 render 执行。核心是 “响应式驱动虚拟 DOM”,通过响应式系统和模板编译自动化优化,减少开发者心智负担。
# 前端重新加载/刷新页面
location.reload()location.reload(true):强制从服务器重新加载页面而不是从缓存中加载location.href = location.hrefhistory.go(0)<meta http-equiv="refresh" content="30">:用于特定的场景,如当页面需要在一定时间后自动更新
# 万向区块链
# 关于堆和栈、一级缓存和二级缓存的理解
- 数据结构的堆和栈(都是逻辑结构)
- 堆:先进先出的,可以被看成是一棵树,如:堆排序。
- 栈:后进先出的、自顶向下。
- 内存分布上的堆和栈
- 栈:局部变量的内存,函数结束后内存自动被释放,栈内存分配运算内置于处理器的指令集中,它的运行效率一般很高,但是分配的内存容量有限。
- 静态存储区:全局变量、static 变量;它是由编译器自动分配和释放的,即内存在程序编译的时候就已经分配好,这块内存在程序的整个运行期间都存在,直到整个程序运行结束时才被释放。
- 动态储存区:堆和栈
- 一级缓存和二级缓存
- 栈使用的是一级缓存, 他们通常都是被调用时处于存储空间中,调用完毕立即释放。栈的效率比堆的高。
- 堆则是存放在二级缓存中,生命周期由虚拟机的垃圾回收算法来决定(并不是一旦成为孤儿对象就能被回收)。所以调用这些对象的速度要相对来得低一些。
- 为什么需要缓存?
- cpu 运行速率很快,但内存的速度很慢,所以就需要缓存,缓存分为一级二级三级,越往下优先级越低,成本越低,容量越大。
- 栈(操作系统):由操作系统自动分配释放 ,存放函数的参数值,局部变量的值等。其操作方式类似于数据结构中的栈。
- 堆(操作系统): 一般由程序员分配释放, 若程序员不释放,程序结束时可能由 OS 回收,分配方式倒是类似于链表。
- CPU 读写速率:
- 寄存器>一级缓存>二级缓存
# Vue 和 React 的区别
- 原理实现上的区别
- 使用上的区别
- 性能上的区别
- 周边生态的区别
# Vue 和 React 的生命周期
- Vue2 的生命周期:beforeCreate -> created -> beforeMount -> mounted -> beforeUpdate -> updated -> beforeDestroy -> destroyed,activated -> deactivated,errorCaptured。
- Vue3 的生命周期:setup -> onBeforeMount -> onMounted -> onBeforeUpdate -> onUpdated -> onBeforeUnmount -> onUnmounted -> onActivated -> onDeactivated -> onErrorCaptured -> onRenderTracked(dev only) -> onRenderTriggered(dev only) -> onServerPrefetch(SSR only)。
- React 的生命周期:constructor(props) -> static getDerivedStateFromProps(nextProps, prevState) ->
componentWillMount-> render -> componentDidMount ->componentWillReceiveProps-> shouldComponentUpdate(nextProps, nextState) -> render ->componentWillUpdate-> getSnapshotBeforeUpdate(prevProps, prevState) -> componentDidUpdate(prevProps, prevState, snapshot) -> componentWillUnmount。
# React
- 挂载阶段:
当组件实例被创建并插入 DOM 中时,其生命周期调用顺序如下:
constructor()static getDerivedStateFromProps()render()componentDidMount()
- 更新阶段:
当组件中的 props 或者 state 发生变化时就会触发更新。组件更新的生命周期调用顺序如下:
static getDerivedStateFromProps()shouldComponentUpdate()render()getSnapshotBeforeUpdate()componentDidUpdate()
- 卸载:
componentWillUnmount()
- 废弃的钩子:
componentWillMountcomponentWillReceivePropscomponentWillUpdate
# React 子组件引入方式
直接通过<Children />引入子组件和通过{props.children}引入子组件有何不同?这个过程中具体发生了什么?
通过
<Children />引入子组件:直接引用,适用于在父组件中明确知道并直接引用子组件的场景。父组件在渲染时会直接调用指定的子组件。父组件对其子组件的依赖性增强,不够灵活。通过
{props.children}引入子组件:动态渲染,适用于在父组件中不确定子组件的情况,父组件在渲染时会根据子组件的动态变化来渲染。用于创建可重用的组件(如布局组件、容器组件等)。它允许父组件将任意子组件作为内容传递给父组件,从而提供更大的灵活性。通过
<Children />引入子组件,React 会立即在渲染父组件时创建该子组件的实例。- 组件直接渲染:当您使用
<Children />引用子组件时,React 会立即在渲染父组件时创建该子组件的实例。 - 父组件受限:父组件需要显式地知道并编写要渲染哪些子组件。这样会导致父组件对其子组件的依赖性增强,不够灵活。
- 组件直接渲染:当您使用
通过
{props.children}引入子组件:- 内容占位:在使用 {props.children} 时,父组件定义了一个位置,任何在父组件标签内放置的内容将被渲染到这个位置。
- 灵活性:传递给父组件的内容可以是任何合法的 React 元素或组件(包括文本、组件、甚至其他 JSX)。这使得父组件能够在不修改其自身代码的情况下接收和渲染不同的子组件。
- 支持多样性:父组件可以接收多个子元素,甚至可以是条件渲染的元素,提供了极大的灵活性和可重用性。
总结:
<Children />:用于直接引用已知的子组件,适用于固定组合。{props.children}:用于动态渲染传递给父组件的内容,适用于高度可重用的组件结构。
# Vue 和 React 渲染组件的方式有何区别
React 渲染机制
- 虚拟 DOM:React 使用虚拟 DOM 来提高性能。组件的状态或属性改变时,React 会先在虚拟 DOM 中计算出差异(diffing),然后再将变化应用于实际的 DOM。
- 组件生命周期:React 通过生命周期方法(如
componentDidMount、shouldComponentUpdate等)来控制组件的渲染和更新。 - 单向数据流:React 的数据流是单向的,组件通过 props 接收数据,状态变化会触发重新渲染。
- 组件通常使用 JavaScript 函数或类来定义,采用 JSX 语法书写 UI。
- 组件的渲染依赖于
render()方法或函数返回 JSX。 - 使用
shouldComponentUpdate()方法或React.memo()进行组件更新优化。 - 在大型应用中,通过
React.lazy和React.Suspense实现代码分割和懒加载。
Vue 渲染机制
- 响应式系统:Vue 使用响应式数据绑定,数据变化时,视图会自动更新,而不需要手动处理 DOM 更新。Vue 内部使用了
Object.defineProperty/Proxy拦截 属性/对象 的 getter/setter 来实现数据的观察。 - 虚拟 DOM:Vue 也使用虚拟 DOM,但它的实现方式相对 React 更加简洁。Vue 在渲染过程中会生成一个虚拟 DOM 树并进行 diffing,最终将最小的差异应用于实际的 DOM。
- 双向数据绑定:Vue 支持双向数据绑定,通过 v-model 等指令,可以在视图和数据之间建立直接的双向绑定。
- 组件定义通常使用 .vue 文件,包含
<template>、<script>和<style>三个部分。 - 组件的渲染通过模板语言定义,使用 Vue 的指令(如
v-if、v-for)来实现。 - 通过
v-once、v-memo等指令进行性能优化,避免不必要的重新渲染。 - 使用计算属性(computed properties)和侦听器(watchers)来优化数据更新和视图渲染。
# React.lazy 和 React.Suspense
React.lazy 是一个函数,用于定义动态导入的组件。它允许你按需加载组件,而不是在应用启动时一次性加载所有组件,从而减少初始加载时间。React.lazy 只能用于组件,不能用于普通的 JavaScript 函数。
- 代码分割:React.lazy 使用 Webpack 的动态导入功能,将组件分割成独立的代码块。当组件被需要时,才会加载这个代码块。
- 懒加载:它返回一个可以在渲染时使用的 React 组件。这种组件在第一次渲染时不会立即加载,而是等到真正需要显示该组件时才加载。
const MyComponent = React.lazy(() => import("./MyComponent"));
React.Suspense 是一个组件,用于处理懒加载组件时的加载状态。它允许你指定一个 fallback 属性,即在组件加载过程中显示的内容(通常是加载指示器或占位符)。在使用 Suspense 时,建议结合错误边界(Error Boundaries)来处理加载过程中的错误。这样可以保证如果组件加载失败,可以优雅地处理错误情况。在 React 18 中,Suspense 还可以配合新的数据获取 API 使用,更加增强了异步和并发渲染的能力。
- 加载状态管理:当使用 React.lazy 加载组件时,React 会在组件加载的过程中触发 Suspense 的加载状态。React.Suspense 会捕获这个加载状态,并在组件加载完成之前显示 fallback 内容。
- Promise 处理:当 React.lazy 返回的 Promise 被解析时,Suspense 会重新渲染其子组件,以显示加载完成后的内容。
- 并发特性:在 React 18 及以后的版本中,Suspense 还与并发特性结合,使得在数据获取和渲染过程中,React 可以更智能地处理 UI 更新。
<React.Suspense fallback={<div>Loading...</div>}>
<MyComponent />
</React.Suspense>
2
3
# 哪个 React 生命周期可以跳过子组件渲染
- React 类组件中:
shouldComponentUpdate(nextProps, nextState) {return nextProps.value !== this.props.value;},只在特定条件下更新。 - 函数组件中:使用
React.memo()来包裹组件,通过传入一个比较函数来决定是否更新。React.memo是一个高阶组件(HOC),用于优化函数组件的渲染性能。它通过浅比较(Shallow Compare) 组件的 props,避免不必要的重新渲染。类似于类组件中的 PureComponent,但专门为函数组件设计。- 直接包裹函数组件时,自动浅比较 props。即第二个参数为空的时候会自动浅比较 props。
- 自定义比较函数:通过第二个参数指定 props 比较逻辑。如果返回 true,则不更新组件;如果返回 false,则更新组件。
- 示例 1:props 是由
{a:1,b:[1,2,3]}变为{a:1,b:[1,2,3,4,5]}这样时,浅比较,b 是数组,引用地址变化,子组件会重新渲染。 - 示例 2:props 是由
{a:1,b:{a:1,b:2}}变为{a:1,b:{a:1,c:3}}这样时,浅比较,b 是对象,引用地址变化,子组件会重新渲染。
- 参考React 浅比较
const MyComponent = React.memo(
({ value }) => {
return <div>{value}</div>;
},
(prevProps, nextProps) => {
return prevProps.value === nextProps.value; // 如果值相等,不更新
}
);
2
3
4
5
6
7
8
缓存回调函数:useCallback:防止回调函数因父组件渲染而重建,导致子组件 props 引用变化。
缓存复杂计算:useMemo:避免每次渲染重复执行高开销计算。
拆分组件与状态隔离:将高频变动的状态封装到独立组件中,避免扩散渲染影响。
避免传递内联对象/函数:
// 这样是错误的,因为每次渲染会生成新的对象触发子组件重新渲染,可以使用 useMemo 或常量的形式传递。 <Child config={{ id: 1, type: "A" }} />1
2优化 context 消费,任何 Context 变化都会触发所有消费者渲染:
const { value } = useContext(MyContext);,拆分 Context 或使用选择器:const value = useContextSelector(MyContext, ctx => ctx.value);。PS:useContextSelector是这个库提供的use-context-selector (opens new window)。列表渲染使用稳定的唯一 key:不要使用索引、随机数或者时间戳等做 key。
使用 PureComponent 仅比较 props 和 state。
# React 类组件中的 setState 和函数组件中 setState 的区别
# React 的 Reconciliation 过程是如何工作的
# forEach 和 map 的区别
# Proxy 概念
# Reflect 概念
# Symbol 概念
# VueRouter
- 路由模式:Hash 模式: createWebHashHistory,History HTML5 模式: createWebHistory,Memory 内存模式: createMemoryHistory -- 适合 Node 环境和 SSR。
- 路由守卫:
- beforeEach:全局前置守卫,当一个导航触发时,全局前置守卫按照创建顺序调用。守卫是异步解析执行,此时导航在所有守卫 resolve 完之前一直处于等待中。
- beforeResolve:全局解析守卫,和 router.beforeEach 类似,在每次导航时都会触发,不同的是,解析守卫刚好会在导航被确认之前、所有组件内守卫和异步路由组件被解析之后调用。是获取数据或执行任何其他操作的理想位置。
- afterEach:全局后置钩子,和守卫不同的是,这些钩子不会接受 next 函数也不会改变导航本身。它们对于分析、更改页面标题、声明页面等辅助功能以及许多其他事情都很有用。
- beforeEnter:路由独享的守卫,直接在路由配置上定义。只在进入路由时触发,不会在 params、query 或 hash 改变时触发。可以将一个函数数组传递给 beforeEnter,这在为不同的路由重用守卫时很有用。当配合嵌套路由使用时,父路由和子路由都可以使用 beforeEnter。如果放在父级路由上,路由在具有相同父级的子路由之间移动时,它不会被触发。
- 从 Vue 3.3 开始,可以在导航守卫内使用 inject() 方法。在 app.provide() 中提供的所有内容都可以在
router.beforeEach()、router.beforeResolve()、router.afterEach()内获取到 - beforeRouteEnter:组件内的守卫,不能 访问 this,因为守卫在导航确认前被调用,因此即将登场的新组件还没被创建。可以通过传一个回调给 next 来访问组件实例。在导航被确认的时候执行回调,并且把组件实例作为回调方法的参数
- beforeRouteUpdate:组件内的守卫,在当前路由改变,但是该组件被复用时调用。
- beforeRouteLeave:组件内的守卫,离开守卫,通常用来预防用户在还未保存修改前突然离开。该导航可以通过返回 false 来取消。
- 完整的导航解析流程:
- 导航被触发。
- 在失活的组件里调用 beforeRouteLeave 守卫。
- 调用全局的 beforeEach 守卫。
- 在重用的组件里调用 beforeRouteUpdate 守卫(2.2+)。
- 在路由配置里调用 beforeEnter。
- 解析异步路由组件。
- 在被激活的组件里调用 beforeRouteEnter。
- 调用全局的 beforeResolve 守卫(2.5+)。
- 导航被确认。
- 调用全局的 afterEach 钩子。
- 触发 DOM 更新。
- 调用 beforeRouteEnter 守卫中传给 next 的回调函数,创建好的组件实例会作为回调函数的参数传入。
- 传参:params、query、hash
// router.js
import { createRouter, createWebHashHistory, createWebHistory, createMemoryHistory } from "vue-router";
import { h } from "vue";
function removeQueryParams(to) {
if (Object.keys(to.query).length) return { path: to.path, query: {}, hash: to.hash };
}
function removeHash(to, from) {
if (to.hash) return { path: to.path, query: to.query, hash: "" };
}
const router = createRouter({
history: createWebHashHistory(), // createWebHistory, createMemoryHistory
routes: [
{
name: "home",
path: "/",
component: () => import("./views/Home.vue"),
beforeEnter: [removeQueryParams, removeHash],
// children:[]
},
{
path: "/users/:id",
component: () => import("./views/UserDetails.vue"),
beforeEnter: [removeQueryParams, removeHash],
},
{
name: "about",
path: "/about",
// component: () => import('./views/About.vue'),
component: () => import("./views/About.vue"),
beforeEnter: [removeQueryParams],
},
],
});
// 路由守卫:全局前置守卫
router.beforeEach(async (to, from) => {
if (
// 检查用户是否已登录
!isAuthenticated &&
// ❗️ 避免无限重定向
to.name !== "Login"
) {
// 将用户重定向到登录页面
return { name: "Login" };
}
// ...
// 返回 false 以取消导航
return false;
// 或者返回一个path字符串
// return '/login';
});
// 或者
// GOOD:确保 next 在任何给定的导航守卫中都被严格调用一次。它可以出现多于一次,但是只能在所有的逻辑路径都不重叠的情况下,否则钩子永远都不会被解析或报错。
router.beforeEach((to, from, next) => {
const global = inject("global"); // 'hello injections'
if (to.name !== "Login" && !isAuthenticated) next({ name: "Login" });
else next();
});
export default router;
// app.js
import { createApp } from "vue";
import App from "./App.vue";
import router from "./router";
const app = createApp(App);
app.provide("global", "hello injections");
app.use(router);
app.mount("#app");
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
- history.pushState()、history.replaceState()、history.back()、history.forward()、history.go()、监听 changestate 事件。使用 history 路由需要在 nginx 配置静态资源,否则会 404。如下:
# ...
location / {
try_files $uri $uri/ /index.html;
}
# ...
2
3
4
5
# pinia
- 可以任意命名
defineStore()的返回值,但最好使用 store 的名字,同时以use开头且以Store结尾。应该在不同的文件中去定义 store。 - 第一个参数是你的应用中 Store 的唯一 ID。defineStore() 的第二个参数可接受两类值:Setup 函数或 Option 对象。
- Option API 中:可以认为 state 是 store 的数据 (data),getters 是 store 的计算属性 (computed),而 actions 则是方法 (methods)。
- 在 Setup Store 中:ref() 就是 state 属性,computed() 就是 getters,function() 就是 actions。
- 使用 Store:在
<script setup>调用 useXXXStore(),store 是一个用 reactive 包装的对象,这意味着不需要在 getters 后面写 .value。就像 setup 中的 props 一样,我们不能对 getters 和 state 进行解构,否则会破坏响应性。可以对 actions 进行解构。 - 为了从 store 中提取属性时保持其响应性,你需要使用 storeToRefs()。它将为每一个响应式属性创建引用。当你只使用 store 的状态而不调用任何 action 时,它会非常有用。
import { defineStore } from "pinia";
// Option API
export const useCounterStore = defineStore("counter", {
state: () => ({
count: 0,
}),
getters: {
doubleCount: (state) => state.count * 2,
doubleCountPlusOne: (state) => state.doubleCount + 1,
},
actions: {
plusOne: () => {
this.count++;
},
increment: (num) => {
this.count += num;
},
},
});
// setup API
import { ref, computed, inject } from "vue";
import { useRoute } from "vue-router";
import { defineStore } from "pinia";
export const useCounterStore = defineStore("counter", () => {
const route = useRoute();
// 这里假定 `app.provide('appProvided', 'value')` 已经调用过
const appProvided = inject("appProvided");
const count = ref(0);
const doubleCount = computed(() => count.value * 2);
function increment() {
count.value++;
}
return { count, doubleCount, increment };
});
// 使用时
import { storeToRefs } from "pinia";
import { useCounterStore } from "./store/counter";
const counterStore = useCounterStore();
const { count, doubleCount } = storeToRefs(counterStore);
const { increment } = counterStore;
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
- 访问 state:
const store = useCounterStore(); store.count++; - 重置 state:
counterStore.$reset();这个方法会重置所有状态,将所有属性重置为初始值。使用 setup 时可以自定义。 - 使用
mapState()辅助函数将 state 属性映射为只读的计算属性:computed: {...mapState(useCounterStore, ['count']), ...mapState(useCounterStore, { myCount: 'count' })},可以取个别名。 - 可修改的 state:使用
mapWritableState()作为代替。但注意你不能像 mapState() 那样传递一个函数。 - 变更 state:
counterStore.$patch({ count: 1 });,可以一次修改多个属性。$patch 方法也接受一个函数来组合这种难以用补丁对象实现的变更。 - 替换 state:不能完全替换掉 store 的 state,因为那样会破坏其响应性。但是,你可以 patch 它。
- 订阅 state:类似于 Vuex 的 subscribe 方法,你可以通过 store 的
$subscribe()方法侦听 state 及其变化。比起普通的 watch(),使用$subscribe()的好处是 subscriptions 在 patch 后只触发一次事件。 counterStore.$subscribe((mutation, state) => {...});- Getter 完全等同于 store 的 state 的计算值。大多数时候,getter 仅依赖 state。不过,有时它们也可能会使用其他 getter。可以通过 this 访问到整个 store 实例。在 ts 中如果在 getter 中用到了 this,需要显式声明返回值类型。
- Getter 只是幕后的计算属性,所以不可以向它们传递任何参数。不过,你可以从 getter 返回一个函数,该函数可以接受任意参数。
- 想要使用另一个 store 的 getter 的话,直接在 getter 内使用就好。
- action 可以是异步的,你可以在它们里面 await 调用任何 API,以及其他 action。
- 想要使用另一个 store 的话,直接在 action 中调用就好。
- 可以使用
mapActions()辅助函数将 action 属性映射为组件中的方法。 methods: {...mapActions(useCounterStore, ['increment']), ...mapActions(useCounterStore, { myOwnName: 'increment' }),},可以设置别名。- 订阅 action:可以通过
store.$onAction()来监听 action 和它们的结果。传递给它的回调函数会在 action 本身之前执行。after 表示在 promise 解决之后,允许你在 action 解决后执行一个回调函数。同样地,onError 允许你在 action 抛出错误或 reject 时执行一个回调函数。
# 防抖、节流
# 重绘与重排
回流是指浏览器需要重新计算样式、布局定位、分层和绘制,回流又被叫重排;触发回流的操作:
- 添加或删除可见的 DOM 元素
- 元素的位置发生变化
- 元素的尺寸发生变化
- 浏览器的窗口尺寸变化
- 修改字体会引起重排
重绘是只重新像素绘制,当元素样式的改变不影响布局时触发。
回流=计算样式+布局+分层+绘制;重绘=绘制。故回流对性能的影响更大。
# JS 中 new 一个对象的过程
- 使用 Object.create
- 以构造函数 Parent 的 prototype 属性为原型,创建一个新的空对象 obj:
const obj = Object.create(Parent.prototype); - 将 obj 作为 this,并传入参数,执行构造函数:
Parent.apply(obj, args); - 返回 obj(如果构造器没有手动返回对象,则返回第一步的对象):
return obj;
function MockNew(Parent, ...args) {
const obj = Object.create(Parent.prototype);
const result = Parent.apply(obj, args);
return typeof result === "object" ? result : obj;
}
2
3
4
5
- 不使用 Object.create
- 创建一个空对象 obj:
const obj = {}; - 让 obj 继承构造函数的的原型 prototype,即将构造函数的作用域赋给新对象(因此 this 就指向了这个新对象):
obj.__proto__ = Parent.prototype; - 将 obj 作为 this,并传入参数,执行构造函数:
Parent.apply(obj, args); - 返回 obj(如果构造器没有手动返回对象,则返回第一步的对象):
return obj;
function MockNew(Parent, ...args) {
const obj = {};
obj.proto = Parent.prototype;
const result = Parent.apply(obj, args);
return typeof result === "object" ? result : obj;
}
2
3
4
5
6
{}创建空对象,原型__proto__指向 Object.prototypeObject.create创建空对象,原型__proto__指向传入的参数(构造函数或者 null)
# 宏任务与微任务
JS 引擎是单线程的,一个时间点下 JS 引擎只能做一件事。而事件循环 Event Loop 是 JS 的执行机制。
JS 做的任务分为同步和异步两种,所谓 "异步",简单说就是一个任务不是连续完成的,先执行第一段,等做好了准备,再回过头执行第二段,第二段也被叫做回调;同步则是连贯完成的。
在等待异步任务准备的同时,JS 引擎去执行其他同步任务,等到异步任务准备好了,再去执行回调。这种模式的优势显而易见,完成相同的任务,花费的时间大大减少,这种方式也被叫做非阻塞式。
而实现这个“通知”的,正是事件循环,把异步任务的回调部分交给事件循环,等时机合适交还给 JS 线程执行。事件循环并不是 JavaScript 首创的,它是计算机的一种运行机制。
事件循环是由一个队列组成的,异步任务的回调遵循先进先出,在 JS 引擎空闲时会一轮一轮地被取出,所以被叫做循环。
微任务和宏任务皆为异步任务,它们都属于一个队列,主要区别在于他们的执行顺序,Event Loop 的走向和取值。
事件循环由宏任务和在执行宏任务期间产生的所有微任务组成。完成当下的宏任务后,会立刻执行所有在此期间入队的微任务。
这种设计是为了给紧急任务一个插队的机会,否则新入队的任务永远被放在队尾。区分了微任务和宏任务后,本轮循环中的微任务实际上就是在插队,这样微任务中所做的状态修改,在下一轮事件循环中也能得到同步。
async 函数在 await 之前的代码都是同步执行的,可以理解为 await 之前的代码属于 new Promise 时传入的代码,await 之后的所有代码都是在 Promise.then 中的回调。
# setState 是宏任务还是微任务
- setState 本质是同步执行,state 都是同步更新,只不过让 React 做成了异步的样子--为了性能优化,会批量处理多次状态更新,合并状态变化,在批量更新结束后,React 会根据最终的状态触发一次重新渲染,React 根据更新后的状态和虚拟 DOM 计算出需要更新的部分,并重新渲染组件。
- 比如在 setTimeout 中时,就是同步,比如在 Promise.then 开始之前,state 已经计算完了。
- 因为要考虑性能优化,多次修改 state,只进行一次 DOM 渲染。
- 日常说的异步是不严谨的,但沟通成本低。
- 所以,既不是宏任务也不是微任务,因为它是同步的。
- PS: react18 中已经把它做成统一的异步形式了,包括在原生事件中的表现。
React 的 合成事件 和 生命周期 默认启用了批处理机制。 在这种情况下,setState 不会立即更新,而是将更新加入到一个队列中,待所有事件回调或生命周期方法执行完后才开始处理。 这种延迟更新可以理解为 任务被加入到下一轮的任务队列中,但它既不是纯粹的宏任务,也不是纯粹的微任务,而是由 React 内部调度机制控制的。
因此:在 React 内部合成事件和生命周期方法中,setState 的更新并不会立即生效,而是会被批量处理。它的行为更类似于 宏任务,因为它通常会在事件循环的下一阶段触发更新,但由 React 内部控制。
在原生事件或异步回调中,如果在 原生事件 或 Promise.then 中调用 setState,React 的批处理机制不会生效,状态更新可能会立即触发,视具体场景而定。在这种情况下,setState 的行为更接近微任务。
不要依赖 setState 后立即获取更新后的状态值,使用 useEffect 或回调函数(如 setState((prevState) => newState))。理解 React 的批量更新机制,避免不必要的状态更新。
// 原生事件中
document.getElementById("btn").addEventListener("click", () => {
setState({ count: count + 1 });
console.log(state.count); // 可能会立即更新
});
// Promise.then 中
Promise.resolve().then(() => {
setState({ count: count + 1 });
console.log(state.count); // 可能会更新
});
2
3
4
5
6
7
8
9
10
11
# 闭包的优缺点
- 闭包是指有权访问另一个函数作用域中变量的函数。创建闭包最常见的方式就是,在一个函数内部创建并返回另一个函数。当函数能够记住并访问所在的词法作用域时,就产生了闭包。
- 闭包通常用来创建内部/私有变量,使得 这些变量不能被外部随意修改,同时又可以通过指定的接口来操作。
- 闭包也会用来延长变量的生命周期。
- 闭包其实是一种特殊的函数,它可以访问函数内部的变量,还可以让这些变量的值始终保持在内存中,不会在函数调用后被垃圾回收机制清除。
- 优点:
- 包含函数内变量的安全,实现封装,防止变量流入其他环境发生命名冲突,造成环境污染。
- 在适当的时候,可以在内存中维护变量并缓存,提高执行效率。
- 即可以用来传递、缓存变量,使用合理,一定程度上能提高代码执行效率。
- 缺点:
- 函数拥有的外部变量的引用,在函数返回时,该变量仍处于活跃状态。
- 闭包作为一个函数返回时,其执行上下文不会被销毁,仍处于执行上下文中。
- 即消耗内存,使用不当容易造成内存泄漏,性能下降。
- 常见使用:节流防抖、IIFE(自执行函数)、柯里化实现
# commonJs 中的 require 与 ES6 中的 import 的区别
# export 与 import 的区别
# CSS 加载是否阻塞 DOM 渲染
# 别人面试
昨天晚上面试题:
- webpack 编译过程
- webpack 热更新
- 从浏览器地址栏输入 url 到用户看到界面发生了什么
- http 的请求报文跟响应报文都有什么
- 说下 http 的缓存(强缓存,协商缓存)
- http 的短连接和长连接
- websocket 和长连接的区别
- 同域名下两个浏览器窗口的 数据共享
- 不同域名下两个浏览器窗口的 数据共享(主要是跟 iframe 的数据共享 )
- css 动画. 栅格布局,自适应布局
- call,apply,bind 的区别
- 闭包
- 柯里化函数
- 防抖,节流
- vue 父子通信的方式
- diff 原理
- vue 路由的实现,从地址改变到渲染组件发生了什么
- vue 的响应式原理
- vue 的生命周期,父子生命周期的顺序
- nextTick 的实现原理
- React.PureComponent 与 Component 的区别
PureComponent会默认实现在shouldComponentUpdate中对 props 的第一层属性做浅比较,然后决定是否更新,相当于做了个性能小优化。不能在PureComponent中使用shouldComponentUpdate。类似React.memo()。
- 如何统一监听 Vue 组件报错
window.onerror:全局监听所有 js 错误,可以捕捉 Vue 监听不到的错误;但它是 js 级别的,识别不了 Vue 组件信息;监听不到 try/catch,可以监听异步报错;window.addEventListener('error', function(){}):同上。参数略有不同。捕获的异常如何上报?常用的发送形式主要有两种: 通过 ajax 发送数据(xhr、jquery...)或动态创建 img 标签的形式;errorCaptured:(errmsg,vm,info)={}:在组件中配置(使用类似钩子函数);监听所有下级组件的错误;返回 false 会阻止向上传播;无法监听异步报错;errorHandler:(errmsg,vm,info)={}:在 main.js 中配置(使用类似钩子函数)app.config.errorHandler=()=>{};Vue 全局错误监听,所有错误都会汇总到这里;但errorCaptured返回 false,不会传播到这里;会干掉window.onerror;无法监听异步报错;
- 如何统一监听 React 组件报错
- 编写
ErrorBoundary组件:利用static getDerivedStateFromError钩子监听所有下级组件的错误,可降级展示 UI;只监听组件渲染时报错,不监听 DOM 事件、异步错误;降级展示只在 production 环境生效,dev 会直接抛出错误。 - 从上可知
ErrorBoundary不会监听 DOM 事件报错和异步错误,所以可以用try-catch,也可用window.onerror; - Promise 未处理的 catch 需要监听
onunhandledrejection:onerror 事件无法捕获到网络异常的错误(资源加载失败、图片显示异常等),例如 img 标签下图片 url 404 网络请求异常的时候,onerror 无法捕获到异常,此时需要监听unhandledrejection。 - JS 报错统计(埋点、上报、统计)用 sentry;sentry 是一个基于 Django 构建的现代化的实时事件日志监控、记录和聚合平台,主要用于快速的发现故障。sentry 支持自动收集和手动收集两种错误收集方法。我们能成功监控到 vue 中的错误、异常,但是还不能捕捉到异步操作、接口请求中的错误,比如接口返回 404、500 等信息,此时我们可以通过
Sentry.caputureException()进行主动上报。
- 编写
- 鉴权
- hmr 热更新原理
- mixin,vue router 的原理
- vue 双向绑定原理
- es6 的新特性
- 如何在 vite 工程的 ts 项目中配置路径别名?
// 1. 打开 vite.config.ts 文件,并导入 resolve 方法和 defineConfig 函数。
import { defineConfig } from 'vite';
import vue from '@vitejs/plugin-vue';
import { resolve } from 'path';
export default defineConfig({
plugins: [vue()],
resolve: {
alias: {
'@': resolve(__dirname, 'src'), // 配置路径别名
},
},
});
// 2. 在 tsconfig.json 文件中添加如下配置:
{
"compilerOptions": {
"target": "esnext",
"module": "esnext",
"strict": true,
"jsx": "preserve",
"moduleResolution": "node",
"esModuleInterop": true,
"skipLibCheck": true,
"forceConsistentCasingInFileNames": true,
"baseUrl": ".",
"paths": {
"@/*": ["src/*"] // 添加路径别名
}
},
"include": ["src/**/*"]
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
# 一个页面打开比较慢,怎么处理?
- 通过 Chrome 的 performance 面板或者 Lighthouse 等工具分析页面性能,通过查看 FP(首次渲染)、FCP(首次内容渲染)、DOMContentLoaded(DCL)、Largest Contentfull Paint 最大内容渲染(LCP)、Load(L)等性能指标,结合资源的加载情况,来判断是哪个过程有问题:加载过程慢还是渲染过程慢?
- 对于加载过程慢:说明是网络问题比较严重。
- 优化服务端硬件配置,静态资源上 cdn 或者是压缩图片、使用 base64 等减少请求数,服务端开启 gzip 等;
- 路由懒加载,大组件异步加载,减少主包的体积;
- 优化 http 缓存策略,强缓存、协商缓存,对于静态资源可以开启强缓存。
- 对于渲染过程慢:可能是接口数据返回的慢,也可能是代码写的有问题。
- 优化服务端接口,提高响应速度;
- 分析前端代码逻辑,优化 Vue/React 组件代码,比如减少重排重绘;
- 服务端渲染 SSR;
- 优化体验:骨架屏,加载动画、进度条。
- 持续跟进:
- 性能优化是一个循序渐进的过程,不像 bug 一次性解决;
- 持续跟进统计结果,再逐步分析性能瓶颈,持续优化;
- 可以使用第三方统计服务,如阿里云 ARMS,百度统计等;
# 大文件上传


- 采用分片上传,将大文件分割成多个小文件,并发上传。
- 采用断点续传,记录已上传的分片,下次上传时跳过已上传的分片。
- 采用多线程上传,充分利用多核 CPU 资源。
- 采用队列管理,控制并发上传数量,避免占用过多带宽。
- 采用服务端合并,将分片上传的结果进行合并,实现完整的文件上传。
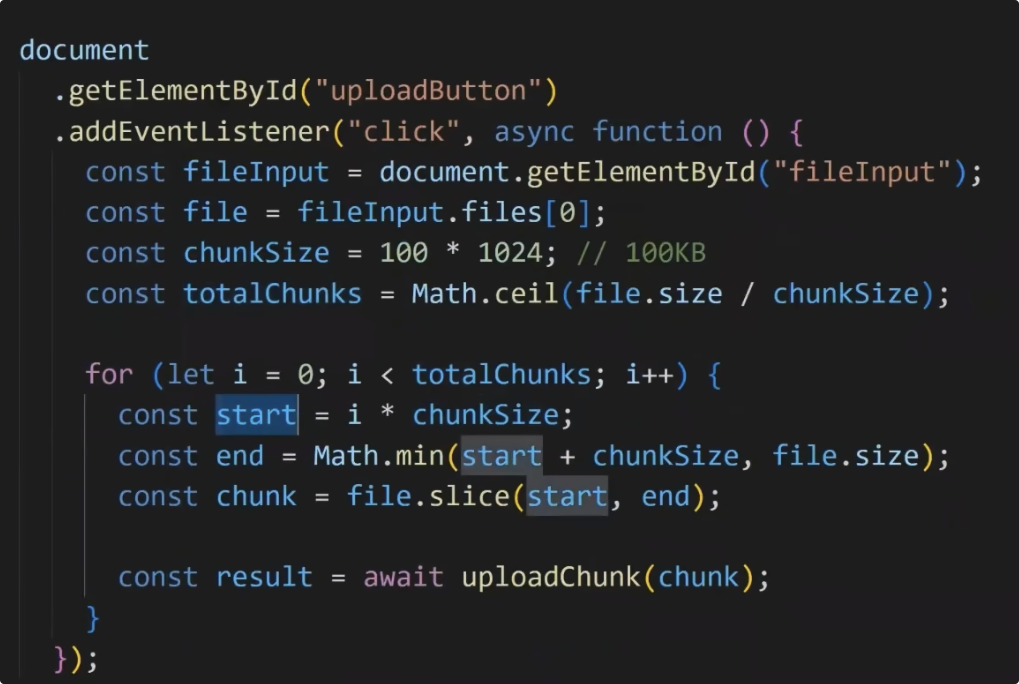
React 大文件上传组件代码示例
import axios from 'axios';
import SparkMD5 from 'spark-md5';
import { UploadOutlined } from '@ant-design/icons';
import { Upload, UploadProps, message } from 'antd';
/**
* 定义检查块状态的响应接口
*/
interface CheckChunksResponse {
uploadStatus: 'uploaded' | 'uploading';
chunkSignsArr?: number[];
}
/**
* 获取文件的MD5哈希值
* @param file 要计算哈希值的文件
* @returns 返回文件的MD5哈希值
*/
const getFileHash = async (file: File): Promise<string> => {
return new Promise((resolve, reject) => {
const fileReader = new FileReader();
fileReader.onload = (e) => {
if (e.target && e.target.result instanceof ArrayBuffer) {
resolve(SparkMD5.ArrayBuffer.hash(e.target.result));
} else {
reject('文件读取结果无效');
}
};
fileReader.onerror = () => reject('文件读取失败');
fileReader.readAsArrayBuffer(file);
});
};
/**
* 处理文件上传逻辑,包括文件切片、断点续传和秒传功能
* @param file 要上传的文件
*/
const handleFileUpload = async (file: File) => {
try {
// 计算文件的MD5哈希值,用于唯一标识文件
const hash = await getFileHash(file);
// 将文件按100KB大小进行切片
const chunkSize = 100 * 1024;
const chunks = [];
let startPos = 0;
while (startPos < file.size) {
chunks.push(file.slice(startPos, startPos + chunkSize));
startPos += chunkSize;
}
// 检查文件是否已存在或部分上传
const { data } = await axios.get<CheckChunksResponse>(
`http://localhost:8080/check-chunks?hash=${hash}&name=${file.name}&chunkTotal=${chunks.length}`
);
// 如果文件已经完全上传,则触发秒传提示
if (data.uploadStatus === 'uploaded') {
message.success('秒传');
return;
}
// 获取已上传的块信息,用于实现断点续传
const chunkSignsArr = data.uploadStatus === 'uploading' && data.chunkSignsArr ? [...data.chunkSignsArr] : new Array(chunks.length).fill(0);
// 创建上传任务列表,仅上传未完成的块
const tasks = chunks.map(async (chunk, index) => {
if (chunkSignsArr[index] !== 0) {
return;
}
const formData = new FormData();
formData.set('name', `${hash}_${index}`);
formData.set('hash', hash);
formData.append('files', chunk);
// 上传每个块,并记录上传进度
await axios.post('http://localhost:8080/upload', formData, {
onUploadProgress: (progressEvent) => {
if (progressEvent.total) {
const progress = (progressEvent.loaded / progressEvent.total * 100).toFixed(2);
console.log(`${index}上传进度:`, progress + '%');
}
},
});
});
// 并发执行所有上传任务
await Promise.all(tasks);
// 请求服务器合并所有上传的块
await axios.get(`http://localhost:8080/merge?name=${file.name}&hash=${hash}`);
message.success('文件上传成功');
} catch (error) {
console.error('文件上传失败:', error);
message.error('文件上传失败');
}
};
/**
* App组件,提供文件上传界面
* @returns 返回上传组件
*/
const App = () => {
const handleChange: UploadProps['onChange'] = async ({ file }) => {
if (!file || !(file as unknown as File).size) {
console.error('上传的文件无效');
return;
}
await handleFileUpload(file as unknown as File);
};
return (
<div style={{ display: 'flex', flexDirection: 'column', alignItems: 'center', justifyContent: 'center', height: '100vh', padding: '20px', width: '100%' }}>
<Upload.Dragger multiple={false} beforeUpload={() => false} onChange={handleChange}>
<p className="ant-upload-drag-icon">
<UploadOutlined />
</p>
<p className="ant-upload-text">拖拽到这里或者<em>点击上传</em></p>
</Upload.Dragger>
</div>
);
};
export default App;
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
# 如何避免大文件重复上传
核心解决方案:文件内容哈希校验
- 实现原理:通过计算文件的唯一哈希值(如 SHA-256)作为文件的"指纹",服务端通过这个指纹判断文件是否已存在。
- 秒传功能(Instant Upload):客户端计算文件哈希,发送哈希到服务端查询,服务端返回文件是否存在,若存在则直接标记为上传成功。否则执行普通分片上传。
- 分块哈希校验(断点续传优化):
// 客户端计算文件哈希
async function calculateFileHash(file) {
return new Promise((resolve) => {
const reader = new FileReader();
reader.onload = async (e) => {
const buffer = e.target.result;
const hashBuffer = await crypto.subtle.digest("SHA-256", buffer);
const hashArray = Array.from(new Uint8Array(hashBuffer));
const hashHex = hashArray.map((b) => b.toString(16).padStart(2, "0")).join("");
resolve(hashHex);
};
reader.readAsArrayBuffer(file);
});
}
2
3
4
5
6
7
8
9
10
11
12
13
14
// 对于超大文件,可以计算分块哈希实现更高效的校验:
async function uploadWithChunkVerification(file) {
const CHUNK_SIZE = 5 * 1024 * 1024; // 5MB分块
const totalChunks = Math.ceil(file.size / CHUNK_SIZE);
const fileHash = await calculateFileHash(file);
// 获取服务端已存在的分块
const { existingChunks } = await fetch(`/api/check-chunks?fileHash=${fileHash}`);
for (let i = 0; i < totalChunks; i++) {
if (existingChunks.includes(i)) continue;
const chunk = file.slice(i * CHUNK_SIZE, (i + 1) * CHUNK_SIZE);
const chunkHash = await calculateChunkHash(chunk);
await uploadChunk({
fileHash,
chunkIndex: i,
chunkHash,
chunkData: chunk,
});
}
// 通知服务端合并文件
await fetch(`/api/merge-file?fileHash=${fileHash}`);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
// 前端哈希计算优化
// 使用Web Worker避免阻塞主线程
function calculateHashInWorker(file) {
return new Promise((resolve) => {
const worker = new Worker("hash-worker.js");
worker.postMessage(file);
worker.onmessage = (e) => resolve(e.data);
});
}
// hash-worker.js
self.onmessage = async (e) => {
const file = e.data;
const hash = await calculateFileHash(file);
self.postMessage(hash);
self.close();
};
// 增量上传(Rsync算法)
// 伪代码
async function uploadChanges(file, previousVersionHash) {
// 获取旧文件的分块签名
const signatures = await getFileSignatures(previousVersionHash);
// 计算新文件的滚动哈希
const newSignatures = calculateRollingHashes(file);
// 比较差异
const diff = findDifferences(signatures, newSignatures);
// 仅上传差异部分
await uploadDiffs(diff);
}
// 浏览器存储记忆
// 使用IndexedDB存储上传记录:
// 存储已上传文件记录
async function saveUploadRecord(file, hash) {
const db = await openDB("upload-cache", 1);
await db.put("files", {
fileHash: hash,
fileName: file.name,
fileSize: file.size,
lastModified: file.lastModified,
uploadedAt: Date.now(),
});
}
// 检查本地记录
async function checkLocalRecord(file) {
const db = await openDB("upload-cache", 1);
const record = await db.get("files", file.name);
if (record && record.fileSize === file.size && record.lastModified === file.lastModified) {
return record.fileHash;
}
return null;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
# 如何实现一个 Promise
class MyPromise {
constructor(executor) {
this.status = "pending";
this.value = undefined;
this.reason = undefined;
this.onFulfilledCallbacks = [];
this.onRejectedCallbacks = [];
const resolve = (value) => {
if (this.status === "pending") {
this.status = "fulfilled";
this.value = value;
this.onFulfilledCallbacks.forEach((cb) => cb(value));
}
};
const reject = (reason) => {
if (this.status === "pending") {
this.status = "rejected";
this.reason = reason;
this.onRejectedCallbacks.forEach((cb) => cb(reason));
}
};
try {
executor(resolve, reject);
} catch (error) {
reject(error);
}
}
then(onFulfilled, onRejected) {
const promise2 = new MyPromise((resolve, reject) => {
if (this.status === "fulfilled") {
setTimeout(() => {
try {
const x = onFulfilled(this.value);
resolvePromise(promise2, x, resolve, reject);
} catch (error) {
reject(error);
}
});
} else if (this.status === "rejected") {
setTimeout(() => {
try {
const x = onRejected(this.reason);
resolvePromise(promise2, x, resolve, reject);
} catch (error) {
reject(error);
}
});
} else if (this.status === "pending") {
this.onFulfilledCallbacks.push(() => {
setTimeout(() => {
try {
const x = onFulfilled(this.value);
resolvePromise(promise2, x, resolve, reject);
} catch (error) {
reject(error);
}
});
});
this.onRejectedCallbacks.push(() => {
setTimeout(() => {
try {
const x = onRejected(this.reason);
resolvePromise(promise2, x, resolve, reject);
} catch (error) {
reject(error);
}
});
});
}
});
return promise2;
}
catch(onRejected) {
return this.then(null, onRejected);
}
}
function resolvePromise(promise2, x, resolve, reject) {
if (promise2 === x) {
reject(new TypeError("Chaining cycle detected"));
} else if (x instanceof MyPromise) {
if (x.status === "pending") {
x.then(
(value) => resolvePromise(promise2, value, resolve, reject),
(reason) => reject(reason)
);
} else {
x.then(resolve, reject);
}
} else {
resolve(x);
}
}
const p = new MyPromise((resolve, reject) => {
setTimeout(() => {
resolve("success");
}, 1000);
});
p.then((value) => {
console.log(value);
}).catch((reason) => {
console.log(reason);
});
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
# 中断 for 循环
- break 是最直接、常规的中断循环的方式。
- 在函数中:可以使用 return。注意:return 只能在函数内部使用。直接在浏览器里跑 for 循环会报错。
- 嵌套循环:可以使用 label 和 break。
- 替代方式:修改循环条件。比如把 i 加到最大。
- 不推荐:抛出异常。
拓展:js 中常见循环的中断方式:
- forEach:是数组方法,用于遍历数组的每一项,无法通过 break 或 continue 中断。中断方式:抛出异常;return 不会中断整个循环,只是跳过当前回调函数的执行。
- map:是数组方法,适用于对数组的每一项进行转换并生成新的数组。无法中断循环,但可以通过 return 提前返回当前项的处理结果或者抛出异常。
- reduce:用于将数组的每一项折叠为单一值,无法中断,但可以通过逻辑控制提前退出计算 - 提前 return。
- filter:用于筛选数组项,无法中断循环,但可以通过条件控制跳过某些项的逻辑处理。
- for...of:遍历可迭代对象(如数组、Set、Map 等)。可以使用 break、continue 和 return 来中断循环。break:终止整个循环;continue:跳过当前循环,继续下一次迭代;return:如果在函数体内,终止整个函数。
- for...in:用于遍历对象的可枚举属性(常用于对象,而非数组)。可以使用 break 和 continue 来控制循环。
- while:是标准的循环结构,可以使用 break、continue 和修改循环条件、抛出异常 来中断。
- do...while: 类似于 while,但会确保代码至少执行一次。可以使用 break 和 continue、抛出异常 来中断。break:终止整个循环;continue:跳过当前循环并检查条件;注意:在 do...while 中,continue 可能会导致死循环,建议谨慎使用。
- for:break、return、label、修改循环条件、抛出异常。
// 执行如下代码,输出:0 1 2 之后卡死。
let i = 0;
do {
if (i === 3) continue; // 跳过当前循环
console.log(i); // 输出会有问题,注意陷阱
i++;
} while (i < 5);
2
3
4
5
6
7
# 前端实现截图
两种情况:
- 对浏览器网页页面的截图。
- 仅对 canvas 画布的截图,比如可视化图表、webGL 等。
实现方式:
- 第三方库:html2canvas(Canvas)、dom-to-image(SVG) - 两种方案目标相同,即把 DOM 转为图片
- 对 canvas 画布截图,因为 canvas 它本身就有保存为图片的功能,它有两个 API 可以用来导出图片,分别是 toDataURL 和 toBlob。toDataURL 方法是将整个画布转换成 base64 格式的 url 地址,toBlob 方法是创造 Blob 对象,默认图片类型是 image/png。
- 浏览器原生截图 API:
navigator.mediaDevices.getUserMedia/getDisplayMedia,可以获取到屏幕的视频流,然后通过视频流生成截图。需要权限。
const a = async () => {
try {
// 调用屏幕捕获 API
const stream = await navigator.mediaDevices.getDisplayMedia({
video: { mediaSource: "screen" },
});
const track = stream.getVideoTracks()[0];
const imageCapture = new ImageCapture(track);
// 捕获屏幕截图
const bitmap = await imageCapture.grabFrame();
// 绘制到 Canvas
const canvas = document.createElement("canvas");
canvas.width = bitmap.width;
canvas.height = bitmap.height;
const ctx = canvas.getContext("2d");
ctx.drawImage(bitmap, 0, 0, bitmap.width, bitmap.height);
// 导出为图片
const imgData = canvas.toDataURL("image/png");
console.log(imgData);
// 停止捕获屏幕
track.stop();
// 如果需要下载图片
const link = document.createElement("a");
link.href = imgData;
link.download = "screenshot.png";
link.click();
} catch (err) {
console.error("屏幕捕获失败:", err);
}
};
a();
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
# 前端音视频流
- 调用摄像头麦克风
navigator.mediaDevices
.getUserMedia({ audio: true, video: true })
.then(function (stream) {
// 使用视频流,例如将其显示在video元素上
var video = document.querySelector("video");
video.srcObject = stream;
video.play();
})
.catch(function (err) {
console.error("Error accessing media devices.", err);
});
2
3
4
5
6
7
8
9
10
11
- 录制视频并保存或者上传
const mediaRecorder = new MediaRecorder(stream);
let chunks = [];
mediaRecorder.ondataavailable = function (event) {
chunks.push(event.data);
};
mediaRecorder.onstop = function () {
const blob = new Blob(chunks, { type: "video/mp4" });
const videoURL = window.URL.createObjectURL(blob);
// 这里可以将videoURL赋值给某个<video>元素的src属性来播放录制的视频
// 或者将blob对象上传到服务器
chunks = []; // 清空chunks数组,以便下次录制
};
// 开始录制
mediaRecorder.start();
// 停止录制
// mediaRecorder.stop(); // 可以在需要的时候调用
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
- 使用 Canvas API 对当前摄像头画面进行截图
const canvas = document.createElement("canvas");
canvas.width = video.videoWidth;
canvas.height = video.videoHeight;
const ctx = canvas.getContext("2d");
ctx.drawImage(video, 0, 0, video.videoWidth, video.videoHeight);
// 将canvas内容转换为图片URL并显示或下载
const imageURL = canvas.toDataURL("image/png");
// 可以在这里将imageURL赋值给某个<img>元素的src属性来显示图片,或者使用a标签的download属性来下载图片
2
3
4
5
6
7
8
# 数组和链表
# 区别
| 比较项 | 数组 | 链表 |
|---|---|---|
| 逻辑结构 | (1)数组在内存中连续; (2)使用数组之前,必须事先固定数组长度,不支持动态改变数组大小;(3) 数组元素增加时,有可能会数组越界;(4) 数组元素减少时,会造成内存浪费;(5)数组增删时需要移动其它元素 | (1)链表采用动态内存分配的方式,在内存中不连续 (2)支持动态增加或者删除元素 (3)需要时可以使用 malloc 或者 new 来申请内存,不用时使用 free 或者 delete 来释放内存 |
| 内存结构 | 数组从栈上分配内存,使用方便,但是自由度小 | 链表从堆上分配内存,自由度大,但是要注意内存泄漏 |
| 访问效率 | 数组在内存中顺序存储,可通过下标访问,访问效率高 | 链表访问效率低,如果想要访问某个元素,需要从头遍历 |
| 越界问题 | 数组的大小是固定的,所以存在访问越界的风险 | 只要可以申请得到链表空间,链表就无越界风险 |
# 使用场景
| 比较项 | 数组 | 链表 |
|---|---|---|
| 空间 | 数组的存储空间是栈上分配的,存储密度大,当要求存储的大小变化不大时,且可以事先确定大小,宜采用数组存储数据 | 链表的存储空间是堆上动态申请的,当要求存储的长度变化较大时,且事先无法估量数据规模,宜采用链表存储 |
| 时间 | 数组访问效率高。当线性表的操作主要是进行查找,很少插入和删除时,宜采用数组结构 | 链表插入、删除效率高,当线性表要求频繁插入和删除时,宜采用链表结构 |
# 操作系统中进程间通信 IPC
进程(Process)是计算机中的程序关于某数据集合上的一次运行活动,是系统进行资源分配和调度的基本单位,是操作系统结构的基础。第一,进程是一个实体。每一个进程都有它自己的地址空间;第二,进程是一个“执行中的程序”。
- 无名管道(pipe)
- 无名管道是一种半双工的通信方式,数据只能单向流动,而且只能在具有亲缘关系的进程间使用。进程的亲缘关系通常是指父子进程关系。
- 速度慢,容量有限,只有父子进程能通讯
- 有名管道 (namedpipe)
- 有名管道也是半双工的通信方式,但是它允许无亲缘关系进程间的通信。
- 信号量(semaphore)
- 信号量是一个计数器,可以用来控制多个进程对共享资源的访问。它常作为一种锁机制,防止某进程正在访问共享资源时,其他进程也访问该资源。因此,主要作为进程间以及同一进程内不同线程之间的同步手段。
- 不能传递复杂消息,只能用来同步
- 消息队列(messagequeue)
- 消息队列是由消息的链表,存放在内核中并由消息队列标识符标识。消息队列克服了信号传递信息少、管道只能承载无格式字节流以及缓冲区大小受限等缺点。
- 容量受到系统限制,且要注意第一次读的时候,要考虑上一次没有读完数据的问题 ;信号传递信息较管道多。
- 信号 (signal)
- 信号是一种比较复杂的通信方式,用于通知接收进程某个事件已经发生。
- 共享内存(shared memory)
- 共享内存就是映射一段能被其他进程所访问的内存,这段共享内存由一个进程创建,但多个进程都可以访问。共享内存是最快的 IPC 方式,它是针对其他进程间通信方式运行效率低而专门设计的。它往往与其他通信机制,如信号量,配合使用,来实现进程间的同步和通信。
- 能够很容易控制容量,速度快,但要保持同步,比如一个进程在写的时候,另一个进程要注意读写的问题,相当于线程中的线程安全,当然,共享内存区同样可以用作线程间通讯,不过没这个必要,线程间本来就已经共享了同一进程内的一块内存。
- 套接字(socket)
- 套接口也是一种进程间通信机制,与其他通信机制不同的是,它可用于不同设备及其间的进程通信。
# 线程间的通信方式
线程是进程的一个实体,是 CPU 调度和分派的基本单位,它是比进程更小的能独立运行的基本单位。线程自己基本上不拥有系统资源,只拥有一点在运行中必不可少的资源(如程序计数器,一组寄存器和栈),但是它可与同属一个进程的其他的线程共享进程所拥有的全部资源。线程间通信主要通过共享内存,上下文切换很快,资源开销较少,但相比进程不够稳定容易丢失数据。
- 锁机制:包括互斥锁、条件变量、读写锁
- 互斥锁提供了以排他方式防止数据结构被并发修改的方法。
- 读写锁允许多个线程同时读共享数据,而对写操作是互斥的。
- 条件变量可以以原子的方式阻塞进程,直到某个特定条件为真为止。对条件的测试是在互斥锁的保护下进行的。条件变量始终与互斥锁一起使用。
- 信号量机制(Semaphore)
- 包括无名线程信号量和命名线程信号量。
- 信号机制(Signal)
- 类似进程间的信号处理。线程间的通信目的主要是用于线程同步,所以线程没有像进程通信中的用于数据交换的通信机制。
# input 如何处理中文输入防抖
使用文本合成系统,当用户使用拼音输入法开始输入汉字时,这个事件 compositionstart 就会被触发,输入结束后触发 compositionend 事件。
input_dom.addEventListener("compositionstart", onCompositionStart);
input_dom.addEventListener("compositionend", onCompositionEnd);
2
# 前端性能优化
前端网站性能优化
- 减少 http 请求数量,浏览器一个域名单次同时发出的请求数量是有限的,每个 http 请求都会经历 tcp 三次握手四次挥手等阶段;css sprites 雪碧图,多张图片合成一张图片,减少 http 请求数,也减少总体积;合并 css、js 文件;路由懒加载 lazyload;
- 控制资源文件加载优先级,css 放在 html 头部,js 放在底部或 body 后面;设置 importance 属性;async、defer 关键字异步加载;
- 静态资源上 cdn,尽量外链 css 和 js,保持代码整洁,利于维护;
- 利用缓存,浏览器缓存;移动端 app 上的 http 缓存只在当前这次 app 存活期间遵循 http 缓存策略,当你的 app 杀死退出后,缓存就会失效。
- 减少重排重绘:基本原理:重排是 DOM 的变化影响到了元素的几何属性(宽和高或位置),浏览器会重新计算元素的几何属性,会使渲染树中受到影响的部分失效,浏览器会验证 DOM 树上的所有其它结点的 visibility 属性,这也是 Reflow 低效的原因。如果 Reflow 的过于频繁,CPU 使用率就会急剧上升。减少 Reflow,如果需要在 DOM 操作时添加样式,尽量使用 增加 class 属性,而不是通过 style 操作样式。
- 减少 dom 操作
- 图标使用 iconfont 替换
- 不使用 css 表达式,会影响效率
- 使用 cdn 网络缓存,加快用户访问速度,减轻源服务器压力,http 缓存只建议加在 cdn 上,应用服务器上不要加缓存,带 hash 的可以加。
- 启用 gzip 压缩
- 伪静态设置
- 合理利用路由懒加载
- 组件库按需加载,使用 es 版本,方便 tree-shaking
- 延迟加载第三方包
- 对资源做 prefetch、preload 预加载;preload 提前加载当前页面需要用到的资源(不执行),prefetch 提前加载下个页面要用到的资源(不执行)。
- 使用多个图片系统域名,使用多个图片系统域名扩大图片的加载请求数量。
- 对域名做 dns 预解析:
<link rel="dns-prefetch" href="//img10.xx.com">,在移动端上有一定效果,因为移动端的 dns 解析比较差。将会用到的域名直接加到 html 的 header 中即可,不需要通过 webpack 去生成。 - 升级 webpack 版本
- 小包替大包,手写替小包,如 dayjs 替换 momentjs
性能优化手段总结:
减少首屏资源大小
- 资源混淆压缩
- 资源加上 gzip
- 压缩图片/使用合适的图片类型/大小
- 图片懒加载
- 合理利用路由懒加载
- 组件库按需加载
- 延迟加载第三方包
- 升级 webpack 版本
- 小包替大包,手写替小包
- webpack.externals 配置第三方库不参与打包,而是在 html 中通过 script 标签直接引入公共 CDN
减少网络消耗/合理利用网络请求
- 资源合并
- 图片做雪碧图/iconfont/base64
- http 缓存/cdn 缓存
- 资源放 CDN
- 对资源做 preload 和 prefetch
- 使用多个图片系统域名
- 对域名做 dns 预解析
优化渲染
- css、js 资源位置,异步加载,设置优先级,防止阻塞 dom 解析,预加载预请求资源,提高响应速度
- 避免重绘重排/减少 dom 结构复杂度:合并 DOM 操作。避免频繁访问布局属性:如 offsetWidth、offsetHeight、clientWidth 等。使用 CSS 动画替代 JavaScript 动画。
- 使用虚拟 DOM,减少 DOM 节点数量,优化结构。
- 懒加载和按需加载,图片懒加载,组件懒加载,使用动态导入(如 React 的 React.lazy())按需加载组件。
- 采用合适的渲染策略,使用 requestAnimationFrame,节流和防抖
- 优化 CSS:减少选择器复杂性,合并 CSS 文件:减少 HTTP 请求次数,使用 CSS 精灵图(sprites)合并小图片。使用 CSS 变量:提高样式的可重用性与管理效率。
- 使用 Web Worker,多线程处理:将处理密集型任务放入 Web Worker 中,避免阻塞主线程,保持 UI 响应。
- 合理使用缓存,利用浏览器缓存:设置适当的缓存策略,利用 HTTP 缓存、Service Worker 等来提升资源加载速度。数据缓存:在前端应用中,使用本地存储(localStorage、sessionStorage)或 IndexedDB 缓存数据,减少不必要的网络请求。
- 优化图像和媒体文件,压缩和优化图片:使用合适的格式(如 WebP),以及压缩图片以减少加载时间。使用 SVG:对于矢量图形,使用 SVG 图片可以减少文件体积,并保持清晰度。
- 减少 HTTP 请求,合并资源,使用 CDN。
- 监测和分析性能
其他关联系统方面
- 长耗时任务,分析耗时长的接口,后端优化
web-vitals库和 performance 进行结合,分析 LCP:主要内容出现的时间,越短越好;FID:输入延迟的时间,低于 100ms 越好;CLS:页面变化的积累量,低于 0.1 越好
- 使用子域名加载资源
- 使用较近的 CDN 或 dns 预解析
- 使用高性能传输方式或方法,http2,quic,gzip...
- 减少 http 请求的数量,合并公共资源、使用雪碧图、合并代码块、按需加载资源
- 减少传输总量或加快传输速度
- 优化图片的加载展示策略,根据网络状况加载图片、图片格式优化、图片展示位置优化
- 减少 cookie 体积
- 使用更有效的缓存策略,keep-alive,expiration,max-age...
- 使用良好的页面布局
- 合理安排路由策略
- 减少反复操作 dom
- 减少重绘和重排
- 异步加载资源
- 公用 css 类
- 使用 GPU 渲染初始动画和图层的合成
- 高效的 js 代码
- 使用防抖和节流对 UI 进行优化
- 使用 web worker 加载资源
- 减少 301 302
- 试试缓存数据的方法 localStorage/sessionStorage/indexedDB
- 无阻塞加载 js,减少并发下载或请求
- 减少插件中的多语言版本内容
- 减少布局上的颠簸,减少对临近元素的影响
- 减少同时的动画
- 制定弱网精简策略
- 针对设备制定精简策略
- 减少页面图层
- js、css 命名尽量简短
- 减少 js 全局查找
- 减少循环和循环嵌套以减少 js 执行时间
- 减少事件绑定
- 组件提取、样式提取、函数提取
- 按照页面变更频率安排资源
- 减少 iframe
- 注意页面大小,特别是 canvas 的大小和占用内存
# React 状态管理
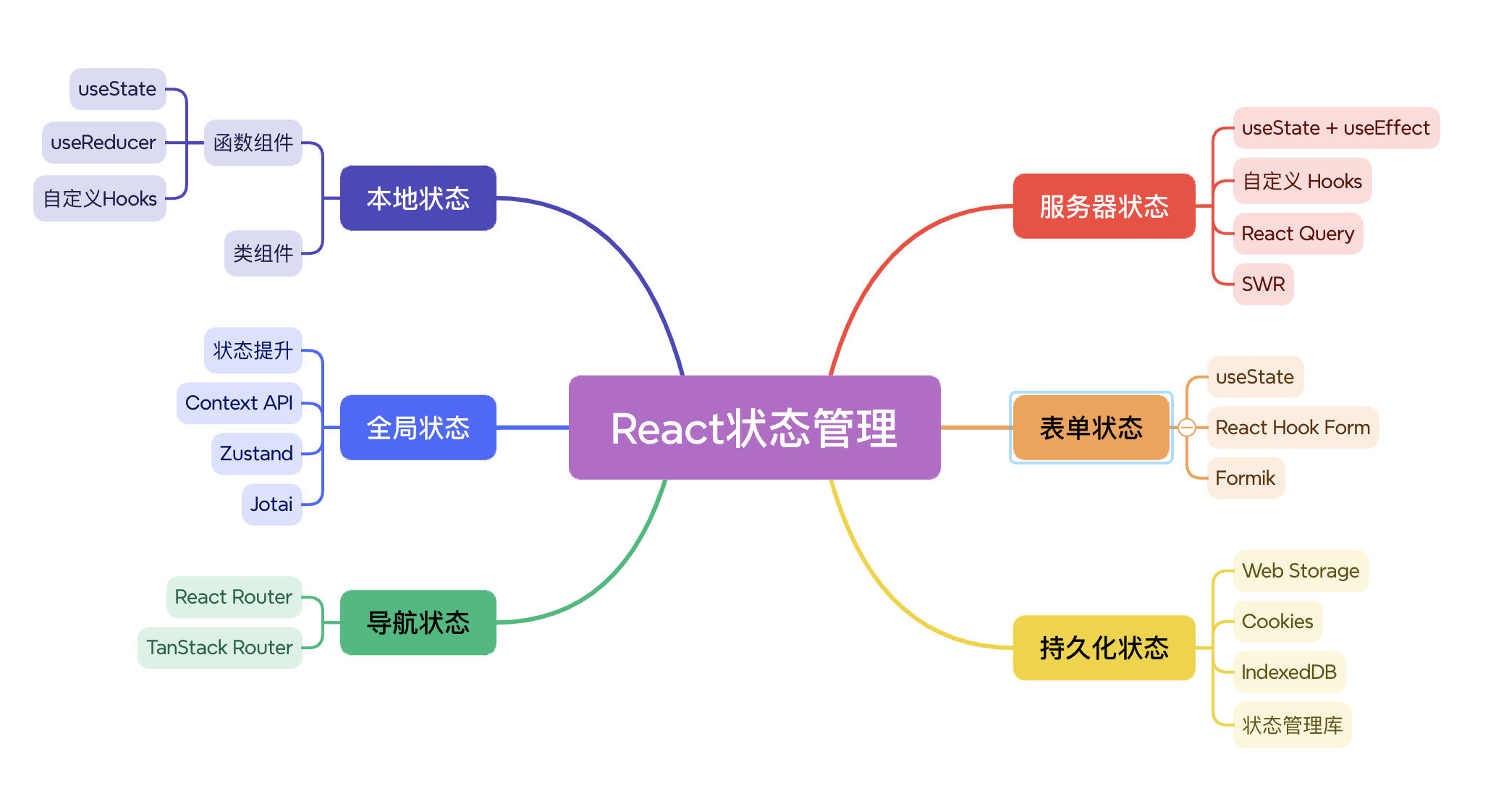
- 本地状态:组件内部管理的数据,这些数据可以影响组件的渲染输出和行为。本地状态是相对于全局状态而言的,它只存在于单个组件中,用于存储那些不需要在整个应用范围内共享的信息。私有性:本地状态是特定于某个组件的,其他组件无法直接访问或修改它。局部性:状态的变化只会影响该组件及其子组件,而不会影响到父组件或其他兄弟组件。生命周期性:随着组件的挂载、更新和卸载,本地状态也会经历相应的生命周期阶段。
- useState:略
- useReducer:用于复杂状态逻辑或状态更新依赖于前一状态的情况。
const [state, dispatch] = useReducer(reducer, initialState); - 自定义 Hooks:封装特定的状态逻辑,并且可以在多个组件之间共享这些逻辑。这不仅提高了代码的复用性,还使得状态管理更加模块化。
- 类组件:在 constructor 中初始化
this.state,再使用this.setState()方法来更新状态。
- 全局状态:指那些在整个应用中多个组件之间需要共享和访问的状态。与本地状态不同,全局状态不局限于单个组件,而是可以在应用的不同部分之间传递、更新和同步。当应用变得越来越大,组件之间的嵌套层次越来越深时,使用 props 逐层传递状态会变得非常麻烦且难以维护。全局状态管理工具可以帮助解决这个问题,它们提供了一种集中管理和共享状态的方式,减少了冗余代码,并提高了开发效率。
- 状态提升: 当需要在兄弟组件中共享状态时,可以将状态提升到父组件。将需要在多个组件之间共享的状态移动到它们的最近公共父组件中进行管理。
- Context API:适合简单的全局状态管理,尤其是当需要避免 props drilling 时。在 React 19 之前,可以使用 MyContext.Provider 的形式来提供共享状态。React 19 中,可以直接使用 MyContext 的形式,省略掉了.Provider。
- Zustand:一个轻量级的选择,适合小型到中型应用,特别是那些注重性能和易用性的项目。
- Jotai:为更细粒度的状态管理提供了可能性,非常适合那些寻求模块化和高效状态管理的开发者。
// store.js
import { create } from "zustand";
const useStore = create((set) => ({
count: 0,
name: "Zustand Store",
increment: () => set((state) => ({ count: state.count + 1 })),
setName: (newName) => set({ name: newName }),
}));
export default useStore;
// component.js
import React from "react";
import { useStore } from "./store";
function Counter() {
const { increment, decrement } = useStore();
// 在组件中,如果只想订阅count状态,可以这样做:不会导致不必要的重新渲染!
const { count } = useStore((state) => ({ count: state.count }));
return (
<div>
<p>Count: {count}</p>
<button onClick={increment}>Increment</button>
<button onClick={decrement}>Decrement</button>
</div>
);
}
export default MyComponent;
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
- 服务器状态:指的是应用与服务端交互相关的状态,包括从服务器获取的数据(如 API 响应)以及请求的状态(如加载中、完成、失败等)。数据一致性:确保前端展示的数据是最新的,并且与服务器上的数据一致。用户体验:提供即时反馈,比如加载指示器、错误消息等,以改善用户的交互体验。缓存策略:合理地使用缓存可以减少不必要的网络请求,提高性能并节省带宽。错误处理:优雅地处理网络故障或其他异常情况,保证应用的稳定性和可靠性。
- useState + useEffect:当只需要从服务器加载一次数据,并且不需要复杂的缓存或重试机制时使用。
- 自定义 Hooks: 当多个组件中有相似的数据获取模式,可以将这部分逻辑提取成一个自定义 Hook 来减少重复代码。
- React Query(现称为 TanStack Query):一个强大的工具,特别适用于需要全面数据获取功能的大型应用。专为 React 应用设计的数据获取、缓存和状态管理库。它通过简化常见的数据操作任务,如发起 HTTP 请求、处理加载状态、错误处理等。
- SWR(stale-while-revalidate):以其简洁性和对实时性的支持而闻名,是那些追求快速集成和良好用户体验的应用的理想选择。它是一个用于数据获取和缓存的 React Hooks 库,由 Vercel 开发。SWR 专为构建快速响应的用户界面而设计,它的工作原理是先返回缓存的数据,然后在后台发起请求获取最新的数据,并在收到新数据后更新 UI。这种模式可以提供即时的用户体验,同时确保数据保持最新。
// ahooks - useRequest 示例
import { useRequest } from "ahooks";
import React from "react";
import Mock from "mockjs";
function getUsername(): Promise<string> {
return new Promise((resolve) => {
setTimeout(() => {
resolve(Mock.mock("@name"));
}, 1000);
});
}
export default () => {
const { data, loading, run, cancel } = useRequest(getUsername, {
pollingInterval: 1000,
pollingWhenHidden: false,
});
return (
<>
<p>Username: {loading ? "loading" : data}</p>
<button type="button" onClick={run}>
start
</button>
<button type="button" onClick={cancel} style={{ marginLeft: 8 }}>
stop
</button>
</>
);
};
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
import { useQuery, useMutation, useQueryClient, QueryClient, QueryClientProvider } from "@tanstack/react-query";
import { getTodos, postTodo } from "../my-api";
const queryClient = new QueryClient();
function App() {
return (
<QueryClientProvider client={queryClient}>
<Todos />
</QueryClientProvider>
);
}
function Todos() {
const queryClient = useQueryClient();
const query = useQuery({ queryKey: ["todos"], queryFn: getTodos });
const mutation = useMutation({
mutationFn: postTodo,
onSuccess: () => {
queryClient.invalidateQueries({ queryKey: ["todos"] });
},
});
return (
<div>
<ul>
{query.data?.map((todo) => (
<li key={todo.id}>{todo.title}</li>
))}
</ul>
<button
onClick={() => {
mutation.mutate({
id: Date.now(),
title: "Do Laundry",
});
}}>
Add Todo
</button>
</div>
);
}
render(<App />, document.getElementById("root"));
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
import React, { useState } from "react";
import useSWR from "swr";
import axios from "axios";
// 自定义的 fetcher 函数,使用 axios
const fetcher = (url) => axios.get(url).then((res) => res.data);
// 自定义的 SWR 配置选项
const swrConfig = {
// 重试次数
retry: 3, // 缓存时间(毫秒)
revalidateOnFocus: false,
shouldRetryOnError: false,
};
function BlogPosts() {
const [page, setPage] = useState(1);
const perPage = 10; // 构建 API URL,包含分页参数
const apiUrl = `https://api.example.com/posts?page=${page}&perPage=${perPage}`; // 使用 SWR 获取文章数据
const { data: posts, error, isValidating } = useSWR(apiUrl, fetcher, swrConfig); // 数据转换:按日期排序
const sortedPosts = posts?.sort((a, b) => new Date(b.date) - new Date(a.date)) || [];
if (error) return <div>加载出错: {error.message}</div>;
if (!posts) return <div>正在加载... {isValidating && "重新验证..."}</div>;
return (
<div>
<h1>博客文章</h1>
<ul>
{sortedPosts.map((post) => (
<li key={post.id}>
<h2>{post.title}</h2>
<p>{post.content}</p>
<small>发布于: {new Date(post.date).toLocaleDateString()}</small>
</li>
))}
</ul>
<button onClick={() => setPage(page - 1)} disabled={page === 1}>
上一页
</button>
<button onClick={() => setPage(page + 1)}>下一页</button>
</div>
);
}
export default BlogPosts;
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
- 导航状态:是指与应用内部页面或视图之间的导航相关的状态。它包括但不限于当前路由信息、历史记录栈、参数传递以及可能的其他元数据。当进行路由导航时,有时需要将前一个页面的状态带到新页面,以确保用户体验的一致性和连续性。通常,在 React 项目中会借助 React Router、TanStack Router 等路由库来实现状态管理。
- React Router
- TanStack Router
- 表单状态:指的是用于保存和管理表单中各个输入元素(如文本框、选择框、复选框、单选按钮等)的数据。这些数据反映了用户与表单的交互情况,并且通常需要被收集起来以便后续处理,例如提交给服务器或用于本地逻辑计算。数据收集:从用户那里获取必要的信息,比如用户的联系信息、偏好设置或者订单详情。验证逻辑:确保用户输入的数据符合预期格式和规则,防止无效或恶意数据进入系统。用户体验:提供即时反馈,比如显示错误消息、动态更新选项或其他增强功能。持久化:即使页面刷新,也能够保持未完成的表单内容,避免用户重新填写。
- 简单表单:使用 useState,它足够简单且无需额外依赖。
- 中等复杂度表单:考虑使用 React Hook Form,特别是重视性能和希望保持依赖树轻量化的时候。
- 复杂表单:选择 Formik,它提供了最全面的功能集,非常适合构建大型、复杂的表单应用。
import React from "react";
import { useForm } from "react-hook-form";
function LoginForm() {
const {
register,
handleSubmit,
formState: { errors },
} = useForm();
const onSubmit = (data) => {
console.log(data);
};
return (
<form onSubmit={handleSubmit(onSubmit)}>
<div>
<label>用户名:</label>
<input {...register("username", { required: "用户名是必填项" })} />
{errors.username && <p>{errors.username.message}</p>}
</div>
<div>
<label>密码:</label>
<input type="password" {...register("password", { required: "密码是必填项" })} />
{errors.password && <p>{errors.password.message}</p>}
</div>
<button type="submit">登录</button>
</form>
);
}
export default LoginForm;
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
import React from "react";
import { Formik, Form, Field, ErrorMessage } from "formik";
import * as Yup from "yup";
// 使用 Yup 定义验证模式
const validationSchema = Yup.object().shape({
username: Yup.string().required("用户名是必填项"),
password: Yup.string().required("密码是必填项"),
});
function LoginForm() {
return (
<Formik
initialValues={{ username: "", password: "" }} // 设置初始表单值
validationSchema={validationSchema} // 定义验证规则
onSubmit={(values, actions) => {
console.log(values); // 可选地,在这里执行异步操作,并在完成后调用 actions.setSubmitting(false)
actions.setSubmitting(false);
}}>
{(
{ isSubmitting } // 获取提交状态
) => (
<Form>
<div>
<label>用户名:</label>
<Field name="username" type="text" /> {/* 创建用户名输入框 */}
<ErrorMessage name="username" component="div" /> {/* 显示用户名的错误信息 */}
</div>
<div>
<label>密码:</label>
<Field name="password" type="password" /> {/* 创建密码输入框 */}
<ErrorMessage name="password" component="div" /> {/* 显示密码的错误信息 */}
</div>
<button type="submit" disabled={isSubmitting}>
{/* 提交按钮,当提交中时禁用 */}登录
</button>
</Form>
)}
</Formik>
);
}
export default LoginForm;
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
- 持久化状态:是指将应用的状态保存到一个持久的存储介质中,以便在用户关闭浏览器、刷新页面或重新启动应用后仍然能够恢复这些状态。持久化状态对于提升用户体验非常重要,因为它可以避免用户丢失数据,并且能够让应用在不同会话之间保持一致的行为。重要性:数据保留:确保用户输入或选择的数据不会因为页面刷新或应用重启而丢失。用户体验:提供更流畅和连续的用户体验,减少重复操作。离线支持:允许应用在没有网络连接的情况下继续工作,并在网络恢复时同步更改。
- Web Storage:适合简单的、短期或长期的客户端状态保存,尤其是用户偏好设置。
- Cookies:主要用于处理认证和跨页面通信,但要注意安全性和数据量限制。
- IndexedDB:一个强大的客户端数据库解决方案,适用于需要存储大量数据或结构化数据的应用。
- Zustand 或 Redux 中间件:结合持久化插件是全局状态管理和持久化的优秀选择,特别适合大型应用和复杂的状态逻辑。
import create from "zustand";
import { persist } from "@zustand/middleware";
import { localStoragePersist } from "zustand/persist";
const persistConfig = {
key: "myStore", // 存储在 localStorage 中的键名
storage: localStoragePersist, // 使用 localStorage 作为存储介质
};
const createStore = () =>
create(
persist((set, get) => ({
count: 0,
increment: () => set((state) => ({ count: state.count + 1 })),
decrement: () => set((state) => ({ count: state.count - 1 })),
})),
persistConfig
);
export const useStore = createStore;
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
// store.js
import { createStore } from "redux";
import { persistStore, persistReducer } from "redux-persist";
import storage from "redux-persist/lib/storage"; // 使用默认的localStorage
import rootReducer from "./reducers"; // 引入根reducer
// 配置redux-persist
const persistConfig = {
key: "root", // 保存数据时使用的键名
storage, // 存储机制
};
// 创建持久化后的reducer
const persistedReducer = persistReducer(persistConfig, rootReducer);
// 创建Redux Store
const store = createStore(persistedReducer);
// 创建persistor对象,用于在应用中集成PersistGate
const persistor = persistStore(store);
export { store, persistor };
// App.js
import React from "react";
import ReactDOM from "react-dom";
import { Provider } from "react-redux";
import { PersistGate } from "redux-persist/integration/react";
import { store, persistor } from "./store"; // 引入刚才设置的store和persistor
import App from "./App";
ReactDOM.render(
<Provider store={store}>
<PersistGate loading={null} persistor={persistor}>
<App />
</PersistGate>
</Provider>,
document.getElementById("root")
);
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
# Vue、React、Angular 避免不必要渲染的机制详解
- React:哪个 React 生命周期可以跳过子组件渲染
- Vue:
v-once:只渲染一次,不更新--<div v-once></div>- computed 属性:缓存计算结果,只有当依赖的数据发生变化时才会重新计算
- v-memo (Vue 3.2+):记忆模板片段--
<div v-memo="[value]"></div> - 函数式组件:无状态组件--
const FunctionalComponent = (props) => h('div', props.value); - 手动 shouldUpdate:自定义函数比较新旧 props
- 列表渲染使用唯一 key
- Angular:
- OnPush 变更检测策略:
@Component({changeDetection: ChangeDetectionStrategy.OnPush}) - 纯管道 (Pure Pipe):相同输入返回缓存结果
@Pipe({pure: true}) - trackBy 函数:优化
*ngFor渲染--<li *ngFor="let item of items; trackBy: trackByFn"></li> - 手动变更检测控制: 手动触发检测--
changeDetectorRef.detectChanges()、标记需要检查--changeDetectorRef.markForCheck()
- OnPush 变更检测策略:
| 技术 | React | Vue | Angular |
|---|---|---|---|
| 核心机制 | 虚拟 DOM diff | 响应式系统 | 变更检测系统 |
| 主要优化 API | React.memo/shouldComponentUpdate | computed/v-once/v-memo | ChangeDetectionStrategy.OnPush/trackBy |
| 函数缓存 | useCallback/useMemo | computed | 纯管道 |
| 列表优化 | key 属性 | key 属性 | 自定义 trackBy 函数 |
| 强制更新 | forceUpdate | $forceUpdate | detectChanges |
| 不可变数据 | 重要 | 推荐 | OnPush 下必需 |
# 前端工程化
前端工程化是指将软件工程的原理和方法应用到前端开发中,以提高开发效率、代码质量和可维护性。随着 Web 应用的复杂度不断增加,传统的前端开发方式已经难以满足需求,因此引入了工程化的概念来更好地管理和优化前端开发流程。前端工程化主要包括以下几个方面:
- 项目构建工具:使用自动化构建工具(如 Webpack, Vite, Parcel 等)来处理和打包前端资源(JavaScript, CSS, 图片等),从而简化开发流程,提升开发体验。这些工具通常支持模块化开发、代码压缩、混淆、热更新等功能。
- 模块化开发:采用模块化的开发模式(如 ES6 模块、CommonJS、AMD 等),可以将代码拆分为更小、更易于管理的部分,有助于团队协作和代码复用。每个模块负责单一功能,并且通过明确的接口与其他模块交互。
- 组件化开发:基于组件的思想构建用户界面,比如 React、Vue 和 Angular 中的组件。组件是独立且可复用的 UI 构建块,它们封装了自身的逻辑和样式,可以在不同的页面或应用之间共享。
- 版本控制:利用 Git 或其他版本控制系统来跟踪代码的变化历史,方便团队成员之间的协作开发,确保项目的稳定性和可回溯性。
- 持续集成/持续部署 (CI/CD):设置 CI/CD 流程自动化测试、构建和部署过程,保证每次代码变更都能经过严格的测试并顺利上线,减少人工操作带来的风险。
- 静态代码分析:通过 ESLint、Prettier 等工具进行静态代码分析,帮助开发者遵循编码规范,提前发现潜在的问题,如语法错误、风格不一致等。
- 性能优化:采取各种措施优化 Web 应用的加载速度和运行性能,例如图片懒加载、服务端渲染(SSR)、客户端缓存策略、减少 HTTP 请求次数、使用 CDN 分发静态资源等。
- 文档生成与维护:保持良好的文档习惯,包括但不限于 API 文档、架构设计文档、开发指南等,这不仅有助于新人快速上手项目,也能为后续的维护提供便利。
- 依赖管理:合理地管理和更新第三方库依赖,确保项目所使用的库是最新的同时避免引入不必要的安全漏洞。常用工具如 pnpm、npm、yarn 可以有效地管理 JavaScript 包依赖。
- 单元测试与集成测试:编写测试用例对组件的功能进行验证,保证在修改代码后不会破坏现有功能;集成测试则用于检查不同模块之间的协同工作是否正常。
- 前端监控体系:本地埋点和线上监控相结合,及时响应故障,收集项目信息并分析。
# Signal
前端框架的演进:HTML/CSS/JS 原生 JS 时代 -> jQuery 时代 -> MVC 框架 如 Backbone.js 时代 -> MVVM 三大框架时代 -> 新兴框架 Svelte/Solidjs/Qwik 等。
从通过命令式的代码到现在通过声明式的代码,通过修改数据驱动视图更新。
Angualr2:脏值检查,通过对比新旧数据值来决定是否更新页面。内部通过 zone.js 提供的变更检测能力来处理异步事件,如用户输入、接口请求、点击事件、异步事件等。通过 onPush 策略,组件 props 有变更时更新,或者手动调用 forceUpdate。
Angular17 中已经使用 Signals 作为其响应式的机制,优化其渲染更新。
# 什么是 Signal
他是一个在访问时 getter 跟踪依赖,在变更时 setter 触发副作用的容器。和 useState 的区别是:useSignal 返回一个 getter 和 setter,而 useState 返回一个 value 和一个 setter。
# 优势
- 更好的性能:自动追踪依赖,实现细粒度更新。
- 惰性求值,减少计算。Signal 只有在被实际使用时才会被监听和更新,依赖项发生变化时也不会立即求值。
- 记忆化,缓存其最后一个值。依赖关系没有变化的计算不需要重新评估,无论访问多少次。
- 更好的开发体验,Signal 可以感知上下文环境,减少心智负担,可以不需要直接指明依赖项,会自动建立依赖关系。
- 运行时性能不错,不需要额外的性能优化 API。
- 适用范围更广,Signal 就是一个普通的 js 对象,可以在任何地方使用,不局限于组件内部。
- Vue3 中的 ref 也是一种 Signal。Vue 通过编译器来实现 signal 优化,编译器可以静态分析模板并在生成的代码中留下标记,使得运行时尽可能的走捷径。也在探索一种 vapor mode 的编译策略,不依赖于 VDOM,而是更多地利用 vue 内置的响应式系统。
# 写一个重发按钮
// ResendButton.tsx
// 点击之后按钮会显示倒计时且不可点击,倒计时5s结束后可以重新点击
import React, { useState, useEffect, useRef } from "react";
const ResendButton = ({ onClick }) => {
const [count, setCount] = useState(0);
const timerRef = useRef(null);
useEffect(() => {
return () => clearInterval(timerRef.current);
}, []);
const handleClick = () => {
if (count > 0) return;
onClick && onClick();
setCount(5);
timerRef.current = setInterval(() => {
setCount((prev) => {
if (prev <= 1) {
clearInterval(timerRef.current);
return 0;
}
return prev - 1;
});
}, 1000);
};
return (
<button onClick={handleClick} disabled={count > 0}>
{count > 0 ? `Retry (${count}s)` : "Resend SMS Code"}
</button>
);
};
export default ResendButton;
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36